私の場合、RとLの音は聞いているだけでは全然、違いがわかりませんでした。
音声入力を使うことで音が違うことを認識できました。
何しろ違いを意識して発音しないと変換してほしい単語にできないので
違いを意識せざる負えません。
しかし自分が言ってることを聞いても、やっぱり違いが分かりません。
まして人が言っている場合に違いがわかるようになる気はしません。
わかるようになれればいいですが・・・
取り合えず、今のままでも「RとLは違う音である」ことを強く認識できたことは収穫です。
Pythonがなくてもメモ帳を使えば英語を話して、うまく変換できるかの確認はできます。
Pythonを使うと、テスト結果を集計することができるので
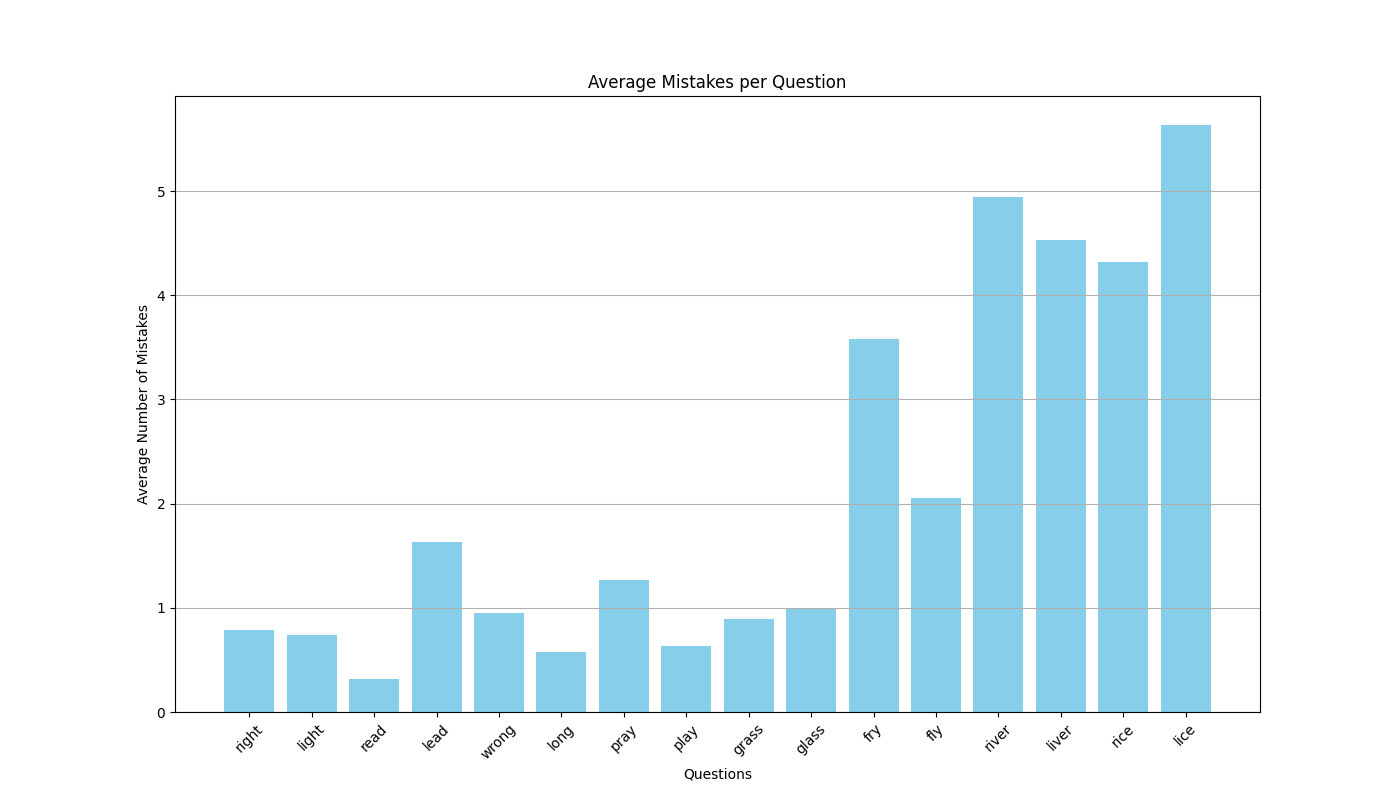
より自分の弱点がわかりやくなります。今回もテスト結果をPythonでグラフにしています。
必要な環境は
Windows11(10は未確認)
事前にな必要ものPythonの実行環境になります。
Youtubeにしてあります。

プログラミングに興味がない方は、こちら↓↓がおすすめ!

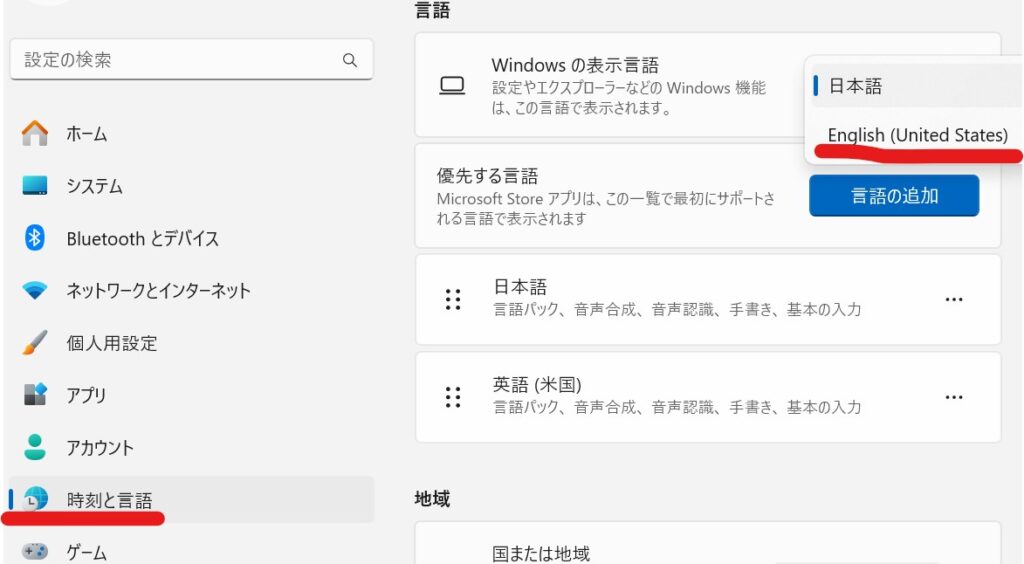
表示言語の変更
Windows標準の音声入力だとWindowsの設定を変えないと英語でしゃべっても
日本語と捉えられうまく英語入力できません。
表示言語を変更すれば英語入力できます。
追記
もしタスクバーに次項「キーボード」のように「ENG US」が選べれば
表示言語を変更しなくても大丈夫です。
もうすでにこうなっているので、これで行けるか分かりませんが、
もしかしたら以下で行けるかもしれません。
私の今の状態が、これをやった状態でした。
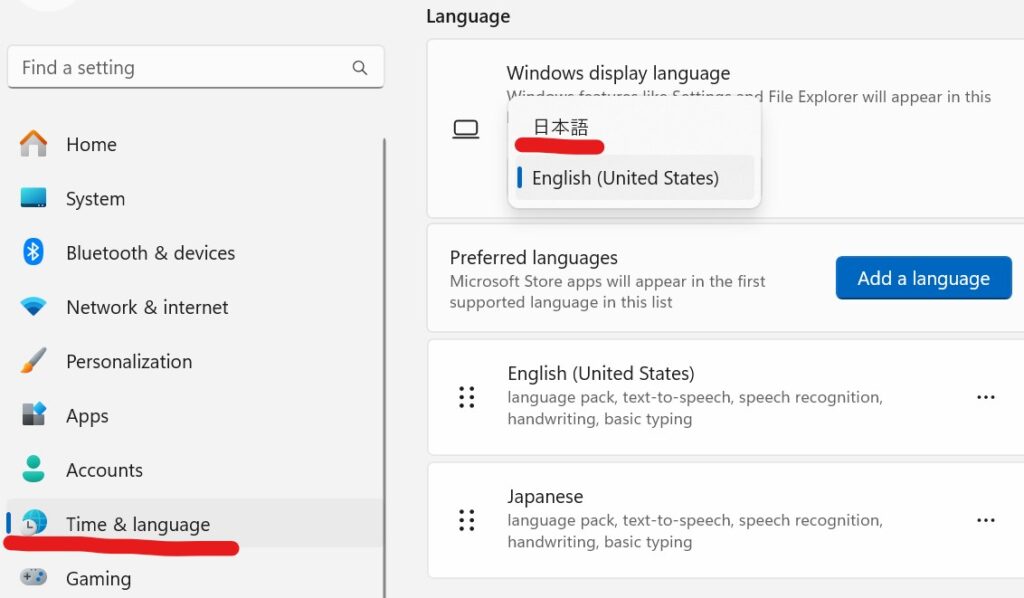
左下のWindowsマークを右クリック→システム→時刻と言語
以下のように英語(米国)と出ていた場合…をクリック
→言語のオプション→キーボードの「キーボードの追加」で「US Qwery」を追加
もしこれで次項「キーボード」のような状態になっていれば、
表示言語は変更しなくてもだいじょうぶです。
やり方
左下のWindowsマークを右クリック→システム→時刻と言語
→Windowsの表示言語をEnglishに変更
サインアウト/サインインが必要になります。
戻すときは、同じ要領ですが英語メニューになっているので以下を参考にしてください。
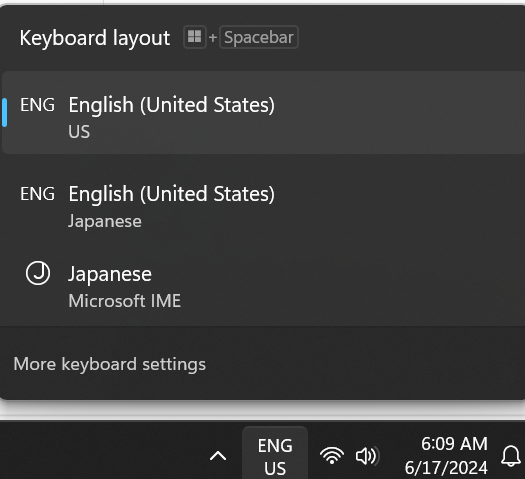
キーボード
Windows下段のタスクバーに「ENG US」とあるのでクリックすると
以下のように選択して切り替えられます。
ENG
音声入力が英語になりますが、キー入力でshift+数字のときキーボードに書いてあるものと違う文字になります。shift+1~9を順番にやってみると!@#$%^&*()
キーボードの表示と異なる部分があります。
JA (後述の「JAを追加する方法」を参照)
音声入力が英語になります。キー入力が英語になります。shift+1~9を順番にやってみると!”#$%&'()キーボードの表示と同じになります。
Japanese Microsoft IME
音声入力日本語になります。キー入力で日本語も使えます。
表示言語英語のとき「JAを追加する方法」
Time & language > Language & region
LanguageにEnglish (United States)がるので右の…をクリック
Language optionsをクリック
Keyboardsでadd a KeyboardでJapaneseをクリック
目次へ
Windows音声入力の精度
日本語で試すと精度がわかります。
以下は私が勝手に考察していることですが、Windows音声入力には二つ特徴があると思います。
・ネットにつながないと動作しないので
音声をマイクロソフトのサーバーに送りAIが音声をテキストに変換して送り返していると思います。
なのでサーバーの混み具合によって返答が遅れるか、返答が返ってこないのではないかと思います。
・音声入力は文意も考慮して変換していると思うので、今回の使い方のように文にならない単語の羅列は、AIが困ってしまい変換がおかしくなるか反応が遅くなる、または止まってしまうのではないかと思います。
なので発音の良しあしとテキスト変換の正確性は参考程度にしたほうがいい。
それでも日本語入力の精度を試すとかなりの精度なので英語もネイティブが話せば
かなりの精度で変換できると思います。
ただ私のようなノンネイティブは音声入力を基準にしすぎるのはかえって混乱するかもしれません。
(私が使っていてそう思いました)
なのでRとLのように自分の発音の仕方で変わるということを確認する程度で、ちまなこになって
音声入力の精度を上げる発音をめざすのは非効率かもしれません。
ということを頭の隅におき、次に具体的にRとLの発音について見ていきます。
目次へ
RとLの違い
個人的に意識していること
Rはウを最初に言うつもりで発音するとうまくいく
fryなどRの前がウの時はそのまま発音すればRになる
Lは下を上の歯の裏にくっつけて発音する
やってみて学んだこと
riceやliceの「ス」というとseとかに変換されてしまう。
音をどうまねてもceに変換されない。
これはもともとceとs系の文字の音の違いが聞き取れないのだから
真似しようとしてもできないはずであると考え
発音記号を調べてceの部分が[s]だということがわかったので
sの発音https://eikaiwa.weblio.jp/column/study/pronunciation/pronounce-s-th-and-sh#ss
https://eikaiwa.weblio.jp/column/study/pronunciation/english-pronunciation-s
を参考に試してみた。
その結果sの発音は簡単で、改善の余地はないはずである。しかしいっこうにceにならない。
いろいろ試しているとsの発音というより「アイ」の発音を強めにいうと
うまくテキストに変換される傾向がわかった。
また、fやpやvなど、うまく発音できていないところも明らかになったので
Youtubeで勉強して、これで試す形で前進できそうな気はしてます。
目次へ
コード
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
Anacondaを使っている場合、condaとpipの問題があるので、以下も参考にしてください。

標準ライブラリ追加で必要なライブラリ
pip install edge_tts playsound pyautogui pandas以下コードを拡張子.pyのファイルで保存、例test.py
python 拡張子.pyで実行
例python test.pyimport asyncio
import edge_tts
import time
import os
import tempfile
from playsound import playsound
import pyautogui
import pandas as pd
from datetime import datetime
# モードの設定('jp'は日本語、'en'は英語)
mode='en'
import re
# 問題の正解リスト
seikai = ['right', 'light', 'read', 'lead', 'wrong', 'long', 'pray', 'play', 'grass', 'glass', 'fry', 'fly', 'river', 'liver', 'rice', 'lice']
def preprocess_text(text):
# 1. 大文字小文字の違いを無視
text = text.lower()
# 2. 短縮形の展開
# text = expand_contractions(text, contractions_dict)
# 3. 記号の削除
text = re.sub(r'[^\w\s]', '', text)
# 4. 不要なスペースの削除
text = text.strip()
text = re.sub(r'\s+', ' ', text)
return text
def compare_texts(answer, correct_answer):
processed_answer = preprocess_text(answer)
processed_correct_answer = preprocess_text(correct_answer)
return processed_answer == processed_correct_answer
def sayafterme(moto,mode):
TEXT = moto
# 音声合成の設定
if mode == 'jp':
VOICE = "ja-JP-NanamiNeural"
else:
VOICE = "en-GB-SoniaNeural"
RATE = "-5%"
# 非同期で音声ファイルを生成する関数
async def amain(output_file) -> None:
communicate = edge_tts.Communicate(TEXT, VOICE, rate=RATE)
await communicate.save(output_file)
# 一時ファイルを作成
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as temp_audio:
OUTPUT_FILE = temp_audio.name
# 非同期関数を実行して音声ファイルを生成
asyncio.run(amain(OUTPUT_FILE))
# ファイルが完全に書き込まれるまで待機
time.sleep(1)
# 音声ファイルを再生し、再生後に削除
if os.path.exists(OUTPUT_FILE):
try:
playsound(OUTPUT_FILE)
# except playsound.PlaysoundException as e:
except Exception as e:
print(f"再生中にエラーが発生しました: {e}")
finally:
os.remove(OUTPUT_FILE) # 一時ファイルを削除
else:
print(f"ファイル {OUTPUT_FILE} が見つかりませんでした。")
# CSVファイルを読み込む関数
def load_dataframe(file_name):
try:
df = pd.read_csv(file_name)
except FileNotFoundError:
df = create_initial_dataframe(seikai)
return df
# 初期のデータフレームを作成
def create_initial_dataframe(seikai):
df = pd.DataFrame(columns=['datetime'] + [f'question_{i+1}' for i in range(len(seikai))])
return df
# 問題を出して間違い数を記録する関数
def ask_questions(seikai):
results = []
qnum = 1
end=0
for correct_answer in seikai:
mistakes = 0
if end==1:
break
while True:
print("Question No",qnum)
print("Say:",correct_answer)
sayafterme(correct_answer,mode)
# 音声入力開始
pyautogui.hotkey('win', 'h')
kaitou = input("回答を入力してください(終了するには '終了' 'end'): ")
# 音声入力停止
pyautogui.hotkey('win', 'h')
# .を削除
kaitou=kaitou.replace('.','')
# 判定
print("Correct answer:",correct_answer)
if compare_texts(kaitou,correct_answer):
print('Result:Correct!'+'\n')
qnum+=1
break
elif 'pass' in kaitou or 'Pass' in kaitou:
print('Result:Pass'+'\n')
qnum+=1
# mistakesよりresultsの最大値が大きいければmistakesに代入resultsが空の場合0 代入
if not results:
mistakes=0
elif mistakes < max(results):
mistakes=max(results)
# mistakes = max(results) if results else 0
break
else:
print('Result:Wrong'+'\n')
if mode == 'jp':
if kaitou.lower() == '終了' or kaitou.lower() == '終了。':
print("プログラムを終了します。")
end=1
break
else:
if 'end' in kaitou or 'End' in kaitou:
print("プログラムを終了します。")
end=1
break
mistakes += 1
results.append(mistakes)
return results
# メインの実行関数
def main(seikai, file_name):
df = load_dataframe(file_name)
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
results = []
# try:
results = ask_questions(seikai)
# ユーザーが中断した場合、実行済みの部分の最大値を取得
if results:
max_value = max(results)
else:
max_value = 0
# 未実行の部分に最大値を入れる
results += [max_value] * (len(seikai) - len(results))
# データフレームに新しい行を追加
new_row = [current_time] + results
df.loc[len(df)] = new_row
# データフレームを保存
df.to_csv(file_name, index=False)
print(df)
# 各質問の平均間違い回数を計算
average_mistakes = df.mean(numeric_only=True)
# 各行で最も多く間違えた数
max_mistakes_per_attempt = df.max(axis=1, numeric_only=True)
# 結果の表示
print(average_mistakes, max_mistakes_per_attempt)
# 実行
if __name__ == "__main__":
file_name = 'results.csv'
main(seikai, file_name)使い方
質問番号と単語が表示され、その単語が読み上げられます
Question No 1
Say: Right
自動的にWindows+Hがおされ音声入力が立ち上がるので
Say:にある言葉を発音してください。
発音後、ドットが表示されたら「New line」と言って回答を確定してください。
正解すると次の問題が出題されます。間違うと同じ問題が出力されます。
回答を入力してください(終了するには ‘終了’ ‘end’): Right.
Correct answer: Right
Result:Correct!
passのあとに「New line」と言えば、その問題はパスされます。
endのあとに「New line」と言えば、プログラムは終了します。
CTRL+Cで強制終了します。
passやendは文の中にあればokですが、
答えたものは、その単語だけでないと正解にはなりません。
全部で16問あり終了すると日付と各質問で正解するまでにかかた回数が
results.csvに保存されます。
ターミナルには、results.csvの内容(question5-10は表示しない)と
各質問の平均回数と各行(日付)の最大値を表示します。
目次へ
分析
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
各質問に対する平均回答数をグラフにしてみます。average_mistakes_per_question.pngというファイルに保存されます。
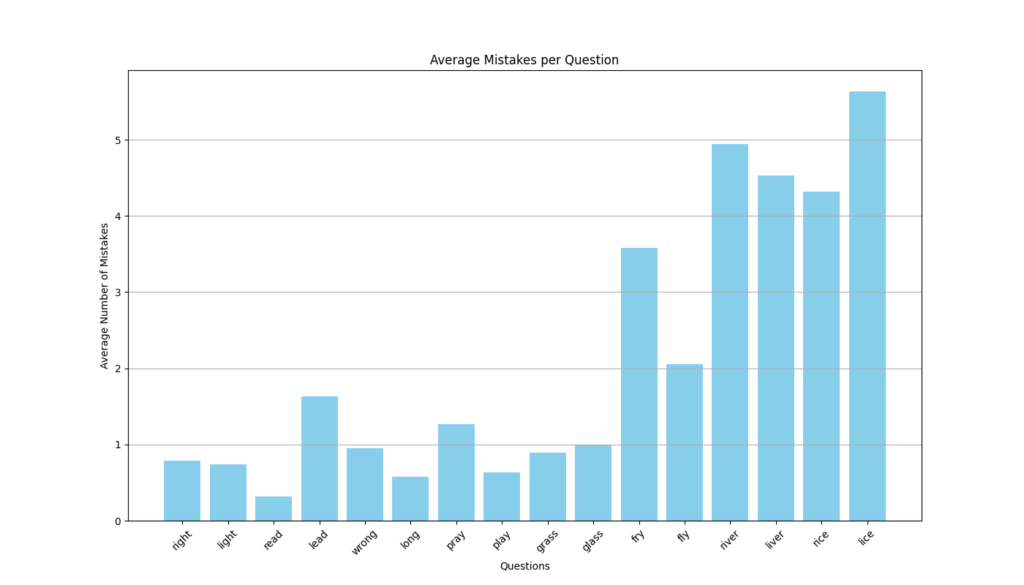
必要なライブラリ
pip install matplotlib以下コードを拡張子.pyのファイルで保存、例bunseki.py
以下、ご自分のものに変更してください
from onseitest2←上のコードのファイル名、.pyはいらない。 import load_dataframe
python 拡張子.pyで実行
例python bunseki.pyimport pandas as pd
# onseitest2はload_dataframeの定義してある.pyファイル
from onseitest2 import load_dataframe
import matplotlib.pyplot as plt
file_name = 'results.csv'
df = load_dataframe(file_name)
# 各質問の平均間違い回数を計算
average_mistakes = df.mean(numeric_only=True)
# 各質問の平均間違い回数をグラフにするためのデータ準備
questions = average_mistakes.index
average_values = average_mistakes.values
# # seikaiリスト
seikai = ['right', 'light', 'read', 'lead', 'wrong', 'long', 'pray', 'play', 'grass', 'glass', 'fry', 'fly', 'river', 'liver', 'rice', 'lice']
# グラフのサイズ設定
plt.figure(figsize=(14, 8))
# 棒グラフの作成
plt.bar(seikai, average_mistakes.values, color='skyblue')
# グラフのタイトルとラベル設定
plt.title('Average Mistakes per Question')
plt.xlabel('Questions')
plt.ylabel('Average Number of Mistakes')
# x軸のラベルを回転
plt.xticks(rotation=45)
# グリッド表示
plt.grid(axis='y')
# グラフを画像ファイルとして保存
graph_file_path = 'average_mistakes_per_question.png'
plt.savefig(graph_file_path)
# グラフの表示
plt.show()まとめ
プログラムは修正すればいろいろな英語学習に活用できると思いますので
ご活用ください。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
目次へ