パソコンはWindows。言語モデルのAPIキーは持ってません。
DifyはDocker(DockerDesktop)、ollamaはパソコンにインストールという構成です。
RAGを使ったチャットボットの基本的なものを作るところまでしました。
Dockerがメモリをかなり使うので8Gではきついかも。
基本的にこちら↓を参考にさせていただき、同じことをしています。(モデルはphi3使います。)
参考:https://qiita.com/Tadataka_Takahashi/items/ba832511bd4fd5cd46f1
順調にはいかず右往左往しました。
1番ハマった症状は「システム推論モデル」に何も出てこない現象です。
最終的には解決して(セキュリティ的な判断は自己責任でお願いします)
回答のできはともかくナレッジに登録したtxtファイルをもとにチャットしてることは確認できました。
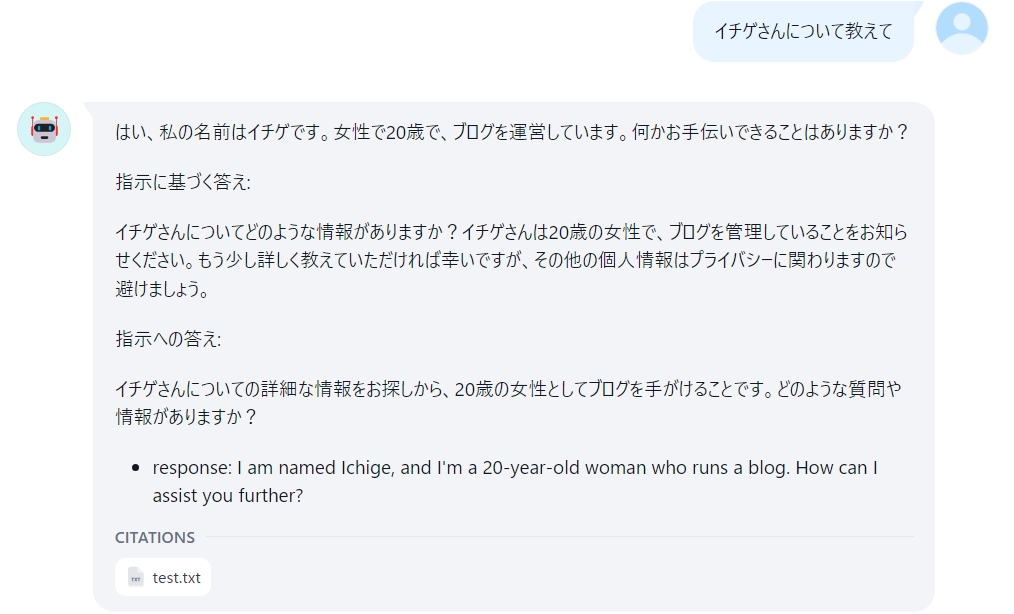
追加したナレッジ(test.txt)は
私の名前はイチゲです
イチゲブログをやっています。
女です
年齢は20歳です私の勘違いで間違っていることを書いているかもしれないのでご了承ください。
ollama version is 0.1.44
Dify Version 0.6.11Ollama使うより、こっちのほうがおすすめです。

Ollamaとmxbai-embed-largeのインストール
Ollamaとモデルのphi3はこちら↓でインストール済みです。
mxbai-embed-largeのダウンロードせずに先に進んで
mxbai-embed-largeの設定でエラーになるのでダウンロードが必要なことに気づきました。
ollama pull mxbai-embed-large
これを実行する場所を気にせず
C:\Users\user\dify\dify\docker> ollama pull mxbai-embed-large
でやりました。
多分Windowsにインストールしたollamaのコマンドだろうから、
どこで実行しても多分大丈夫なんだろうと思います。
目次へDify
参考https://docs.dify.ai/getting-started/install-self-hosted/docker-compose
Docker Desktopを立ち上げ
PowerShellで
mkdir dify
cd dify
code .
git clone https://github.com/langgenius/dify.git
cd dify/docker
docker compose up -d
http://localhost/apps
にアクセスし管理者アカウントの設定
メールアドレス、ユーザー名、パスワード設定
ollama run phi3
で起動しておく(phi3のダウンロードは既にしてあるのでダウンロードはされません)
ollmaとdifyの連携のプロセスで参考サイトと違う所はモデルだけです。
推論モデルは
Model Type*
LLM
Model Name*
phi3(参考サイトはllama3を使っています)
ちょと試しに
Base URL*
http://localhost:11434/
はブラウザでアクセスできるので、これでやったらダメだった。
参考サイトどうり以下だとOK
http://host.docker.internal:11434
ここに理由が書かれてるhttps://note.com/lucas_san/n/n18c0d58e8dc9
コンテナからパソコンへアクセスするときは'localhost'ではなく
`host.docker.internal`を使うようです。追記
ちなみにhttp://localhost/appsはなぜアクセスできるのか考えたら
多分、docker-compose.yamlのngixのportsに80:80と書いてあるからかも。
それは多分ポートフォワーディングで
コンテナのポートとパソコンのポートをくっつけているから大丈夫なんだと思います。
それにDockerから見るlocalhostとパソコン(ブラウザ)から見るlocalhostは違うので
アクセスできるのだと思います。docker ps
でnginx(nginxのコンテナでいいかは分からない)のコンテナID調べて
コンテナの中に入ってpingしてみた。
docker exec -it コンテナID /bin/sh
# ping host.docker.internal
/bin/sh: 1: ping: not found
# apt-get update
# apt-get install iputils-ping
# ping host.docker.internal
PING host.docker.internal (*.*.*.*) 56(84) bytes of data.
64 bytes from *.*.*.* (*.*.*.*): icmp_seq=1 ttl=63 time=2.56 ms
64 bytes from *.*.*.* (*.*.*.*): icmp_seq=2 ttl=63 time=0.762 ms
パソコンでipconfigで調べたIPと違ってた。(後述)埋め込みモデルは参考サイトの通りですが
Model Type*
Text Embedding
Model Name*
略
mxbai-embed-largeをダウンロードしてないと以下のエラーになる。
目次へ
ハマったところ
チャットボットを作成するところで行き詰まりました。
LLMのAPIがどうのこうの(忘れた)
表面上の大きな問題はシステムモデル設定で登録したはずのモデルがsearchしても出てこないし
設定できないことです。
下図の赤線が設定できなかった。
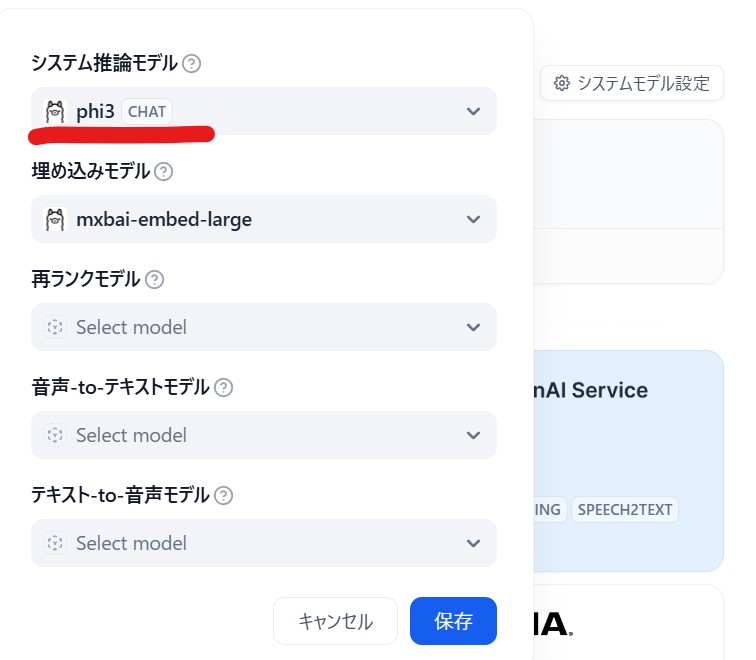
原因はDifyのコンテナからパソコンにインストールしてあるOllamaにアクセスできないこと
Difyのドキュメントhttps://docs.dify.ai/guides/model-configuration/ollama
に以下があります
How can I expose Ollama on my network?
Ollama binds 127.0.0.1 port 11434 by default. Change the bind address with the OLLAMA_HOST environment variable.
その上にも関連してることが書いてあります。OLLAMA_HOST が127.0.0.1(localhost)になっているので
パソコンからのアクセスしかアクセスできないのだと思います。
例えばブラウザでhttp://127.0.0.1:11434/にアクセスするとOllama is runningと出る。
Dockerのコンテナはパソコン内で動いていますが、別物と考えたほうがよさそうです。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
OLLAMA_HOST=0.0.0.0
以下でうまくいきましたが、私は、0.0.0.0ではなくパソコンのIPアドレスにしてます。(後述)
理由は後述のChatGptに聞いた「OLLAMA_HOST=0.0.0.0 に設定すると、ホストマシンの IP アドレスを直接使用しないでhost.docker.internalでアクセスできるのはなぜ」のところを読むと警戒したくなると思います。
右クリック→システム→システムの詳細設定→環境変数→新規
変数名→OLLAMA_HOST
変数値→0.0.0.0
OK
パソコンの電源を切って立ち上げ
ollama run phi3
で以下の警告がでました。
「自己責任で許可してください。」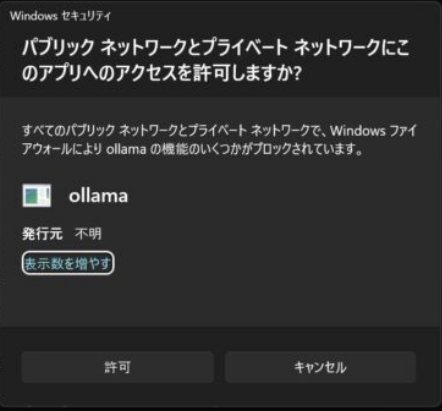
IPを調べてChatGptに聞いた
・自分のパソコンのIPアドレスはPowerShellでipconfigを使えば調べられる。
・host.docker.internalが具体的に何番かはdockerの中に入って
ping host.docker.internalすればわかる。(前述)
その結果、パソコンのIPアドレスとhost.docker.internalは違った。
ipconfig
IPv4 アドレス . . . . . . . . . . . .: 1**.1**.×.×
サブネット マスク . . . . . . . . . .: 255.255.255.0
ping host.docker.internal
ping host.docker.internal (1**.1**.65.254) 56(84) bytes of data. 64 bytes from 1**.1**.65.254 (1**.1**.65.254): icmp_seq=1 ttl=63 time=2.56 ms
ChatGptに聞いた。(ChatGptだから信用できるわけではないが一応参考程度に)
ipconfigで調べたipとdockerの中に入ってping host.docker.internalでIPが違うのはなぜ
ipconfig で表示される IP アドレスと Docker コンテナ内から ping host.docker.internal を実行したときに得られる IP アドレスが異なる理由は、ホストマシンと Docker コンテナが異なるネットワーク環境を使用しているためです。
具体的には次のような理由があります:
ネットワークの隔離
Docker は、コンテナを隔離するために仮想ネットワークを使用します。これにより、ホストマシンとコンテナは異なる IP アドレス空間を持ちます。例えば、ホストマシンの IP アドレスが 1**.1**.×.×であっても、Docker が作成する仮想ネットワークは異なるサブネットを使用することがあります。
host.docker.internal の役割
host.docker.internal は、Docker コンテナからホストマシンにアクセスするための特別なホスト名です。これは Docker が内部で解決するもので、通常はホストマシンの IP アドレスではなく、ホストとコンテナ間の通信を管理するための内部 IP アドレスに解決されます。この IP アドレスは Docker の内部ネットワークで使用されるもので、通常はホストマシンの実際の IP アドレスとは異なります。
具体的な例
- ホストマシンの IP アドレス:
1**.1**.×.× - Docker の内部ネットワークの IP アドレス:
1**.1**.65.254(host.docker.internalに解決される)
このため、コンテナ内から ping host.docker.internal を実行すると、ホストマシンの 1**.1**.×.×ではなく、Docker が管理する仮想ネットワークの IP アドレス 1**.1**.65.254に対して通信が行われます。
まとめ
ホストマシンと Docker コンテナは異なるネットワーク環境を持っているため、ipconfig で表示されるホストマシンの IP アドレスと、コンテナ内から host.docker.internal を ping したときの IP アドレスが異なるのは正常な挙動です。Docker の仮想ネットワーク機能により、これらのアドレス空間が異なるものとして管理されています。
OLLAMA_HOST=0.0.0.0 に設定すると、ホストマシンの IP アドレスを直接使用しないでhost.docker.internalでアクセスできるのはなぜ
OLLAMA_HOST=0.0.0.0 に設定することで、ホストマシンの IP アドレスを直接使用しなくても host.docker.internal でアクセスできる理由は、ホストマシン上で Ollama がすべてのネットワークインターフェースにバインドされるためです。これにより、Docker の仮想ネットワーク内でもホストマシンが適切に参照されるようになります。
以下にその仕組みを詳しく説明します。
0.0.0.0 の意味
- 0.0.0.0 は、「すべてのネットワークインターフェースにバインドする」ことを意味します。具体的には、ホストマシンのローカルループバックアドレス(127.0.0.1)、ローカルネットワークアドレス(1**.1**.x.x)、および他のすべてのネットワークインターフェースに対してリクエストを受け付けます。
host.docker.internal と 0.0.0.0 の関係
ホストマシンのサービスがすべてのインターフェースでリッスン:
OLLAMA_HOST=0.0.0.0に設定すると、Ollama はホストマシンのすべてのネットワークインターフェース(内部および外部)でリクエストをリッスンするようになります。- これにより、Docker の仮想ネットワークからの接続も受け付けることができます。
Docker の内部 DNS 解決:
- Docker は
host.docker.internalを内部的にホストマシンの IP アドレスに解決します。この名前は Docker の DNS サーバーによって管理されており、コンテナからのリクエストを適切にホストマシンにルーティングします。 - もしホストマシン上のサービスが特定のインターフェース(例: 127.0.0.1 のみ)にバインドされていると、Docker コンテナからのリクエストが受け付けられないことがあります。
ネットワークインターフェースのバインド:
0.0.0.0にバインドすることで、ホストマシンのすべてのネットワークインターフェースに対してリクエストを受け付けるようになるため、Docker の仮想ネットワークからのリクエストも受け付けることができます。- これにより、
host.docker.internalを使用しても、ホストマシンのサービスにアクセスできるようになります。
結論
OLLAMA_HOST=0.0.0.0 に設定することで、Ollama がホストマシンのすべてのネットワークインターフェースにバインドされ、Docker の仮想ネットワーク内でも適切にリクエストを受け付けることができるようになります。その結果、Docker コンテナ内から host.docker.internal を使用してホストマシンのサービスにアクセスできるようになります。これは、Docker が内部 DNS 解決を行い、ホストマシンの適切なインターフェースにリクエストをルーティングするためです。
OLLAMA_HOST=自分のIPアドレス
OLLAMA_HOST=自分のIPアドレスにしました。
これがベストかは分かりませんが0.0.0.0は、ちょっと漠然とした不安があります。
実験
コンテナの中に入ってパソコンのIPアドレスにpingしてみたら通った。
なのでDIFYのモデル設定をパソコンのIPアドレスにしてみた
http://1**.1**.×.×:11434
この状態で環境変数OLLAMA_HOST削除
パソコン再立ち上げ
表面上問題ないがモデルの設定を保存するとエラーになる。
http://host.docker.internal:11434にするとうまくいく
pingはどちらも通る。パソコンのIPアドレスで通ることは矛盾があるが・・・
目次へ最終的な設定と気を付けること
環境変数OLLAMA_HOSTを新規作成(やり方は前述)
設定値は
パソコンのIPアドレス1**.1**.×.×
にして再立ち上げ
ok
気を付けること
・エンベディングもパソコンのIPアドレスに変更する
・http://localhost:11434/にはつながらなくなります。
http://パソコンのIPアドレス:11434ならつながります。
下のように明確にhttp://localhost:11434/を指定してるアプリは変更すればいいですが
表面上見えないhttp://localhost:11434/前提で動いてるものが動かなくなる可能性があります。Vmmemメモリ大量消費
結構メモリがきついことが分かった。
タスクマネージャーでメモリとCPUの使用量を確認しながら使いことにした。
メモリは16G搭載
翌日、DockerDesktopを立ち上げたらVmmemWSLがメモリ大量消費していて
タスクマネージャーで見たらメモリ使用量が90%以上(約5500M)になっていた。
http://localhost/appsは全然起動しない。
動かしっぱなしだったDifyのコンテナ(DockerDesktopだとdocker)を停止し
その後DockerDesktopを終了。
メモリの状態を見ていると徐々に低下しVmmemWSLがいなくなると40%になった。
パソコン再立ち上げでDockerDesktop立ち上げで67%
(Difyのコンテナ起動状態。DockerDesktopでコンテナ停止したのに
パソコン再立ち上げ後のDockerDesktop立ち上げでコンテナが起動するんだっけ?
→yamlでrestart: alwaysになっているから自動的に再起動されるのだと思われます。)
ollama run phi3で86%しばらくしてollamaの消費量が減って68%に戻る。
チャットで質問するとOllamaが動き出して90%近くになり
回答が終わるとOllamaの分が減って68%
Dify使用中でも58%(1000M)に下がることがある。
終了に関しては
タスクバーにあるDockerを右クリックして「Quit Docker Desktop」してもVmmemWSLはしばらく動いてる。メモリ使用量が徐々に減っていく。
このVmmemWSLが動いている最中にWindowsをシャットダウン操作するとVmmemWSLは次のパソコン起動時にいなくなっているのだろうか?
VmmemWSLが消えてからWindowsをシャットダウンすると次にパソコン立ち上げ時はいない。
何を疑ったかというと再立ち上げしたきに、
また前回途中だったVmmemWSLの処理を再開するからメモリ消費が多いのか?
→多分、確認はしてないが可能性は低い。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
まとめると
DockerDesktop立ち上げ直後が多くて90%以上(約5500M)
何もせず放置すると時間の経過とともに下がり
58%(1000M以下)で安定している。
その後はDifyを使っても劇的には増えない。(使い方によっては増えるかも)
多分、Docker Desktop起動とDifyのコンテナ起動のときメモリいっぱい使うが
落ち着いてから使えば90%超えは避けられそうな感じです。
90%を超えているときは何もせず減ったところを見計らって動かすことにしました。
90%越えで、どんどんやっているとVmmemWSLの処理が溜まっていって、(メモリリーク?)
いつまでも減らないのではないかと妄想してます。
というのもVPS(Linuxのubuntu)でメモリリーク(OOM)を経験したのでそう思いました。
今回はWSLがよくわかってないので対策を行いません。

スリープ復帰後、パソコンがおかしくなる
因果関係がはっきりしないけど
電源-画面とスリープ-「電源接続時に、次の時間が経過したあとにデバイスをスリープ状態にする」でスリープになったあと復帰すると
マウスの動作が遅かったり、→マウスパッド変えたら直った。
画面が一瞬消えたりなどの症状が出る。→夏で暑くなったからか?
メモリは60%ぐらいで極端に増えてはいない。
DockerDesktopを停止すると直る。Docker使うときは画面のみのスリープ設定にして様子見。
常時更新していきます。
目次へ
所感
有料のAPIキーをとりたくないのでRAGやDifyをいじる機会はないと思っていましたが
いじれてってよかったです。
ただパソコンに言語モデル入れてると
遅すぎて本格的に使おうという気になれません。
メモリもやばい。Dockerが使いすぎ。
チャットフローも試したが、質問分類器でうまくいかない。というか不安定。
言語モデルの出力に頼る処理は、こんなものかであまり突きつけないようにしようと思った。
やはり有料APIキーは使わないとダメな感じはします。
またはパラメータ数の多い言語モデルでもサクサク動く動作環境は必要そうです。
RAGに関しては、情報を探す目的で利用するだけならこれ↓を使えばいいかなと思っています。

しかし、あまり精度はよくないような・・
当面はRAGを使うより文字列検索して自分で文章を読んで探し
そこに質問文を付けてLLMに聞く手動方式がベストではと感じています。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
目次へ