この記事はDifyにGemini 1.5 ProのAPIキーを無料で取得して
設定できるのか確認するのが目的です。
私はGoogleアカウントは持っていますが今までGoogleの有料製品は使ったことがありません。
ですのでクレカ登録してません。今回もしてません。
ここを見る限り無料って書いてあります。
デフォルトはGemini 1.5 Flashになっていますが
Gemini 1.5 Proに変えれば情報が変わります。
https://ai.google.dev/pricing?_gl=1*14g76z8*_ga*MTgxMjUzMTgxMy4xNzE4OTQ2NDA2*_ga_P1DBVKWT6V*MTcxODk0NjQwNS4xLjEuMTcxODk0ODE2My42MC4wLjgxNzI2MjQ5&hl=ja
さすがに無料では使える使用量が1日あたりのリクエスト数が50回までと少ないですが、
今まで試せなかったことが無料で試せるのはありがたいことです。
(2025/9/15追記)Gemini 1.5 は非推奨になっています。都度、情報は更新されますのでご注意ください。
https://ai.google.dev/gemini-api/docs/models?hl=ja#gemini-1.5-flash
今までクレカ登録と従量課金というのが嫌で使うことがなかった
言語モデルのAPIキーをやっと使うことができました。
環境、Windows11、DockerDesktop
Dify
クラウド版
https://cloud.dify.ai/signinへアクセスGoogleかGitHubで続行で使えます。
無料プランの説明https://dify.ai/pricing
GPTの無料トライアル200回と書いてある。
今回Geminiを追加しますがgpt-3.5-turboとかが無料(200回?)で使えるようです。
また、作ったアプリを無料で公に公開できるっぽい。
というか最初から右上に「公開する」って書いてあるけど、
これをクリックで公開なのか?よくわからん。
URLはアプリを実行をクリックすると出てくる。
そのURLは宣伝しなきゃ誰も分からないかもしれないけど。
お試しだけで使おうとする人は公開しないほうがいいかも。
公開して誰かが使うと、とんでもない長い文章を入れるかもしれないので。
有料の言語モデルのAPIキーを使う場合、気をつけた方がいいと思います。
無料のGemini 1.5 ProAPIキーでも使用量の制限があるので自分で使う分が減りますね。
ということで、
GPTの200回無料は温存してGemini 1.5 ProのAPIキーで使っていこうと思います。
でも使用制限がいまいちわかっていないので、使いすぎて使えなくなったら嫌なので
公開できるようなものができるまで
主に次項のローカールでDocker使ってやっていこうと思います。
Docker
こちらは言語モデルが用意されてません。
後述のGemini 1.5 ProのAPIキー取得すれば言語モデルが使えます。
WindowsのDocker Desktopで導入しました。
Difyを導入したときの様子です。参考にしてください。
上の記事はOllamaで動かす記事ですが
今回のようにAPIキーが使えるのであればOllamaは不要です。
上の記事のollama run phi3の前だけで動きます。ハマった原因もOllama使ったためです。
ただ上の記事の下のほうに書きましたが
Docker Desktopはメモリ使用量に注意して使ってください。
それでもOllamaを立ち上げなければだいぶメモリ使用量は違うので
この点でもAPIキーはよかったです。
「公開する」をクリックして「アプリを実行」で
立ち上がったアプリのurlはhttp://localhost/chat/M9eK39*****でした。
localhostの下にあるので公には公開されてません。
Gemini 1.5 ProのAPIキー取得
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
Difyを立ち上げる。
私の場合DockerDesktopを起動。Dify(Difyのコンテナ)は自動で立ち上がる。
http://localhost/appsにアクセス→右上の自分の名前をクリック→設定→モデルプロバイダ→Geminiのセットアップ→Get your API Key from Google→get api key in google ai studio
法的通知(良ければ)全部チェック→続行→Develop in your own environmentkeyのGet API key→キーAPIキーを作成→Safety Setting Reminder(良ければ)→OK→
「API キーをまだ作成していない場合は、新しいプロジェクトで API キーを作成します」の【キー新しいプロジェクトで API キーを作成】をクリック
「APIキーが作成されました」がでたらコピー
DifyのGeminiのAPIキーに貼り付け
モデルプロバイダのモデルにGeminiが追加される。
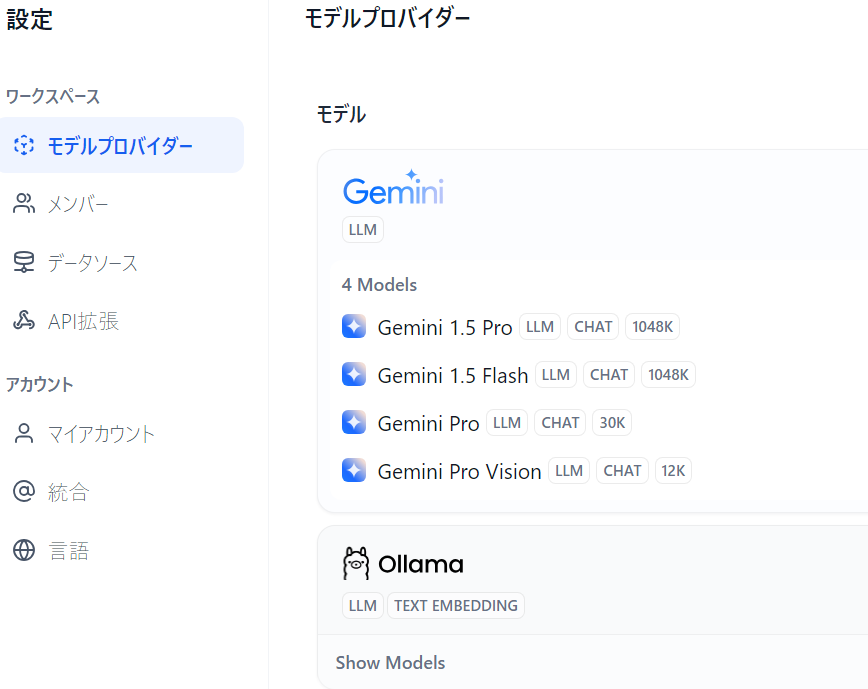
Google AI Studioには以下のように無料であることが確認できる。

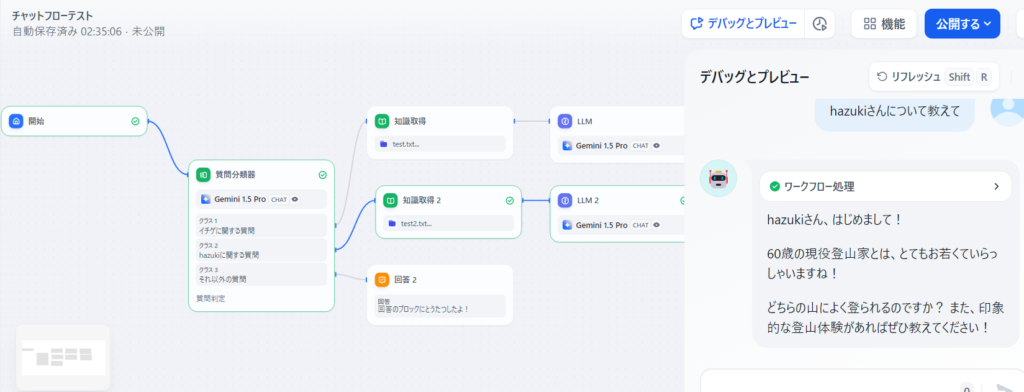
Difyのチャットフローで作ってみた
使い方は、よくわかってません。
会話としては変ですがtest2.txtに書いた内容を元に回答してきたのを確認しました。
ただ、もう1個のtest.txtのほうはうまくいかず、不安定です。
test2.txtの中身
私の名前はhazukiです
登山家をやっています。
男です
年齢は60歳です
気づいたこと、乱書き
チャットフロー
・質問に必ず特定の文字が含まれる場合は、質問分類器を使用するよりIF/ELSEでif文を使ったほうが
基調なLLM(この処理でLLMのAPIキーを消費してるはず)を使用しなくて済むし明確に分岐できる。
・LLMにメモリ設定があり、多分それがONになっていると、同じ質問しても同じ答えが返ってくる。
・ナレッジで対応するファイルをクリックすると検索回数が見れる。知識(test.txt)をベースに回答してないときここを確認した0回のままだった。同じ構造で知識(test2.txt)の回答は、ちゃんと知識をベースにした回答をするし検索回数も都度増えてる。知識をもとに回答してないときは検索回数が増えないことで知識を見に行ってないことが確認できるのかも。その見に行かない原因は調査中。
・知識をベースにした回答が返ってこないとき、会話直後に「ログを表示」がポップアップするのでクリックしてトレースで知識取得を見ると、出力”result”: []と空っぽになっている。
うまくいくときは”result”: [にいろいろ書いてある。
・”result”: []が空っぽになっているのは、質問に対して知識取得でデータが抽出できていない。
その質問は知識にないと判断されている。
知識取得で単独で▷をクリックして元のデータにある文章aを入れて実行するとresultが空でなくなる。
なのでチャットで無理やりその文章aをクエリに入れて質問を作ると、
その文章に反応して知識をもとに回答が出てくる。
任意の質問に対して知識取得で、ちゃんと知識が引っ張られないのはインデックス方法が「経済的」を選んでいるからか。→Ollama(mxbai-embed-large)を動かして高品質にしてベクトル検索(再ランクなし)にしたら反応するようになった。
ただ、知識のもとになる2つのtxtファイルは、ほとんど同じ形式で「経済的」選んだのに
一方は反応して一方は反応しない。ここはムラがあるだけで追及してもしょうがないかも。
RAGを成功させるためには、この質問に対して知識取得がうまくできるかどうかが
大きな役割を果たしそうです。
・トレースのLLMを見ると「データ処理」のところが
最終的にLLMに渡される(API使って問い合わせるところ)プロンプトのように思われる。
多分ここが1番重要な確認するべきところだと思います。
以下のような形式になっていた。
{
"model_mode": "chat",
"prompts": [
{
"role": "user",
"text": "***",
"files": []
},
{
"role": "assistant",
"text": "***",
"files": []
},
{
"role": "user",
"text": "***",
"files": []
}
]
}これって、どの言語モデルでも共通のフォーマットなのかな。
実際に、このフォーマットで言語モデルに送っているかは分からないが(この後、言語モデルごとに変えるとか)
言語モデルには何入れても勝手に解釈して返答してきそう。
現段階の私の認識では、前の段階で埋め込みとか難しいことをやっているが、
結局ここに出てくるのはナレッジから抽出された文章と質問を合わせたもので、
それをLLMにプロンプトとして送っていると思っています。
以上を踏まえ改めて作って整理してみました。↓
DifyではなくDjangoでチャットアプリをつくってみた
イチゲチャット(Beta版)500エラーになっていることがある。(調査中)
所感
自分のパソコンで言語モデルを動かすOllamaとスピードが全然違う。
Gemini 1.5 ProのAPIキーは無料なので
Dify以外にも今までできなかったことが色々試せそうでありがたいです。
例え50回とは1日で復活するのはうれしい。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)