Pythonで表計算を扱う場合Excelで操作するものが多いです。
しかしExcel持っていない人もいるでしょう。
この記事ではExcelではなくcsvファイルで表計算を扱います。
具体的にはデータの入ったリスト(1次元配列)を作り1行ずつ追加して表を作っていきます。
作成する各行は色々実用的な方法で作っていきます。
表データを扱うのに便利なpandasというライブラリを使います。
初心者にもわかりやすいようにできるだけ専門用語は使わないようにしています。
プログラマーが任意に決められないコードは緑色にしました。
緑色以外はプログラムする人が自由に決めていいワードになります。
(塗り忘れもあるかもしれません。)
最終的にはgoogleスプレッドシートにこの表をPythonで作ります。
(csvファイルをgoogleスプレッドシートで読み込む)
Google Colaboratoryでもpyperclip以外の部分は実行できます。
Pythonをインストールしないでも無料で使える
Google Colaboratoryについてはこちらの記事をご覧ください。
パソコンにExcelがインストールされていなくても無料の Web 版 Officeで見られます。なのでネットで紹介されているExcelのPython操作の勉強も有料EXCELなくても基本的に大丈夫です。
WindowsでJupiternotebookなどプログラミング環境構築はこちら

当記事のコードをJupiternotebookにコピペして使うと
’などが全角になるときがありますので半角に直してください。
見出し行(ヘッダー行、カラム名)を1行用意する
まず見出し行だけの表を作ります。
表の1行目は各列(column)を表す名前のあつまりなのでcolumnsという変数名になってます。
縦の1列目は行indexという変数名です。
今回1行ずつ追加していくのでindexは最初に決めないで表を作っていきます。
コード
import pandas as pd
list1=[]
columns1 =["Col1", "Col2", "Col3", "Col4", "Col5"]
df1=pd.DataFrame(data=list1, columns=columns1)
df1コード解説
import pandas as pd
解説:pandasライブラリを使えるようにする。
pandasと記述するのが大変なのでpdという短い名前に変更している。
list1=[]
解説:中身が空のlist1というリストを定義
columns1 =[“Col1”, “Col2”, “Col3”, “Col4”, “Col5”]
解説:colums1という変数に項目行の名前を定義
df1=pd.DataFrame(data=list1, columns=columns1)
解説:この関数(pandas.Dataframe)が使われている。
df1という表(class)定義、中身のdataは空、見出し行はcolums1で定義したもの
実行結果

リストに文字列を代入し1行追加する
リストに直接文字を書き行に追加する方法です。
インデックス(1列目)は「くだもの」にします。
コード
list1=['いちご','バナナ','リンゴ','みかん','スイカ']
df1.loc['くだもの']=list1
df1コード解説
list1=[‘いちご’,’バナナ’,’リンゴ’,’みかん’,’スイカ’]
解説:list1に追加する行のデータを,区切りで入れる両サイドは[]をつける。
df1.loc[‘くだもの’]=list1
解説:表df1に「くだもの」というインデックス(1列目)をつけたlist1の中身を1行追加する。
実行結果

リストに変数を1個ずつ代入し行を追加する
計算結果などをリストに代入し表に追加する場合です。
例として今回は2行追加します。
1行目は0から5までの数字
2行目は上の行を2倍した数字
インデクスは、こういうこともできるんだということを知ってもらうために
適当に10と直前のfor文で使った変数iにしてみます。
(中身のデータとの関連はまったくありません。)
コード
list1.clear()
list2=[]
for i in range(5):
list1.append(i)
list2.append(i*2)
df1.loc[10]=list1
df1.loc[i]=list2
df1コード解説
list1.clear()
解説:list1の中身をクリア
list2=[]
解説:list2という新しいlistを定義
for i in range(5):
解説:iに0から1ずつ増やした数を代入しインテンド(右にずれている行)されている部分をiが5になるまで繰り返す。
list1.append(i)
解説:list1にiを追加する。list1は1ループ目で[0]。2ループ目で[0,1]・・・[0,1,2,3,4]というふうに,で区切られて数字が追加されていく。
list2.append(i*2)
解説:list2に2倍したiを代入していく。
df1.loc[10]=list1
解説: 表df1に10というインデックス(1列目)をつけたlist1の中身を1行追加する。
df1.loc[i]=list2
解説: 表df1にiの値(for文を抜けるときにiは4になっている)をインデックス(1列目)につけたlist2の中身を1行追加する。
実行結果
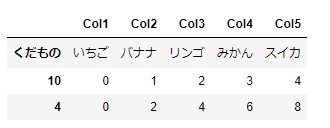
WEBからコピーした文字列を行に追加する
例としてyahooのピンポイント天気の気温を5個選択して
右クリック→コピーしたものを表に追加します。
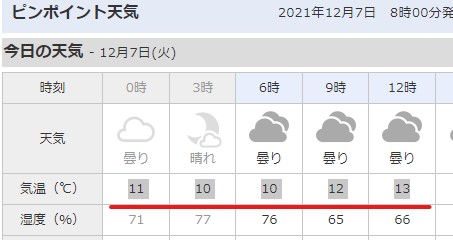
コピーしたものをJupiternotebookに張り付けて実行するとエラーになります。
普通、コードではなく、ただの文字を書いて実行すると、
その文字が表示されてエラーにはなりません。
これはJupiternotebookで見やすいようにtabの部分を→に変換して表示してるためです。
(ちなみに半角スペースでもエラーなります。連続した数字だったらエラーになりません。)
Google Colaboratoryでもエラーになります。
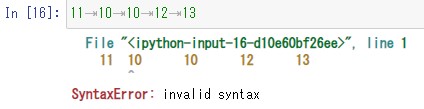
なので変数=にそのまま貼り付けて使用するとエラーになります。
tabは文字として扱えるので、貼り付けるときに””または”で囲って変数に代入すれば扱えます。

pyperclipライブラリを使用する方法もあります。
インストールが必要ですが
私の場合(Windows)
pip install pyperclipだけで使えるようになりました。
pyperclip インストールでググってみてください。
Google Colaboratoryではインストールはできましたが
実行するとエラーになりました。
スタック・オーバーフローのこの質問を見ると
クリップボードを使用するものは
MacやGoogle Colaboratoryでは使えないか大変そうです。
なので以下はWindows+JupiterNotebook での話になります。
pyperclip を使ってコピーしたものを変数に代入すると
エラーなく使える文字列に代わります。
具体的には
import pyperclip
str1=pyperclip.paste()
str1str1の中身を見てみると、先ほどと同じになります。
'11\t10\t10\t12\t13'
しかしタブの部分が¥tになっています。
この記号はタブ文字(水平タブ)を表すエスケープシーケンス(特殊文字)です。
このデータをリストデータにできるように処理します。
replace('\t',',')で\tを,(カンマ)に置き換えます。'90,20,30,10,10'
replace(‘,’)で,がデータの区切りになり[’90’, ’20’, ’30’, ’10’, ’10’]というリストになります。
コード
注意:このコードを実行する前にyahooのピンポイント天気の気温を5個選択して
右クリック→コピーしてください。つまりクリップボードに気温5個がコピーされている状態。
list3=[] import pyperclip str1=pyperclip.paste() str2=str1.replace('\t',',') list3=str2.split(',') df1.loc['気温(℃)']=list3 df1
コード解説
list3=[]
解説:list3という新しいlistを定義
import pyperclip
解説:pyperclipを使えるようにする。
str1=pyperclip.paste()
解説:str1にコピーした文字列をペースト(代入)
str2=str1.replace('\t',',')
解説:str1は'11\t10\t10\t12\t13'となっているので\tを,へ変換'90,20,30,10,10'、結果をstr2に代入。
list3=str2.split(',')
解説:str2を,ごとに要素にわけ['90', '20', '30', '10', '10']というリストにする。結果をlist3へ。
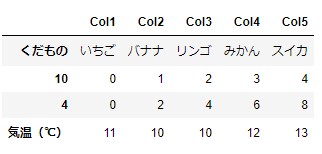
df1.loc['気温(℃)']=list3
解説:表df1に気温(℃)というインデックス(1列目)をつけたlist3の中身を1行追加する。
実行結果

文字列を数字のリストに変換する
少し脱線します。
上のlist3は文字列のリストです。文字列は数字ではないので全部の平均値を計算するなどに使えません。これを数字のリストに変換するには
string_list = ['90', '20', '30', '10', '10']
list3 = [int(i) for i in string_list]
print(int_list)
結果[90, 20, 30, 10, 10]
ちなみにこの処理はChatGptで
「pythonで['90', '20', '30', '10', '10']という文字列のリストを数値のリストに変換する方法」と聞いたら答えてきた方法です。
このようにChatGpt等(Microsoft Bing、Google Geminiでも同じように使える)も活用していきましょう。
columnsとindexを変更する
続きです。
見出し行(1行目)とインデクス(1列目)に書いてる内容を変更してみます。
コード
df1_new = df1.rename(columns={'Col1': '1列目','Col2': '2列目','Col3': '3列目','Col4': '4列目','Col5': '5列目'}, index={'くだもの': 'フルーツ',10: '整数',4: '2の倍数'})
df1_newコード解説
renameを使って見出し行の各項目をそれぞれ:で分けて変更したい文字を書きます。
例えば’Col1′: ‘1列目’ はCol1を1列目に変更という意味。
indexも同様です。結果をdf1_newに代入。これで出来上がりです。
実行結果
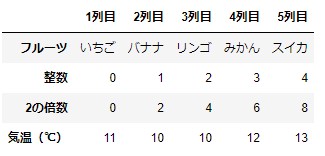
csvファイルに出力
出来上がった df1_new をcsvファイルに出力します。
コード
df1_new.to_csv("hyou.csv")コード解説
かっこの中に”で任意のファイル名を指定するだけです。
.csvはcsvファイルを意味する拡張子です。
出力された結果をメモ帳にドラッグ&ドロップするとメモ帳で見れます。
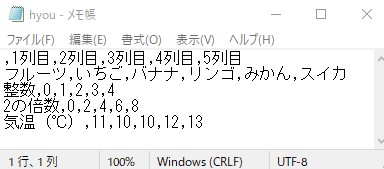
各要素が,で区切られています。改行はそのまま。
,から始まってますが今回表の0,0に要素が何もないため,始まりです。
この,について読み込むときに影響するので次の項目も読んでください。
メモ帳でcsvファイルを保存するときは注意が必要です。
普通に保存するとテキストファイルで保存されてしまうからです。
csvでファイルを保存するには
ファイル→名前を付けて保存→ファイルの種類をすべてのファイルにする→ファイル名を任意のファイル名.csvにして保存
出来上がったcsvファイルをgoogleスプレッドシートにアップロードする方法です。
この記事を参照してください。最終的にExcelにも変換できます。
csvファイルをExcelで開いたら文字化け
先ほど作ったhyou.csvをEXCELで開くと以下のように文字化けすることがあります。
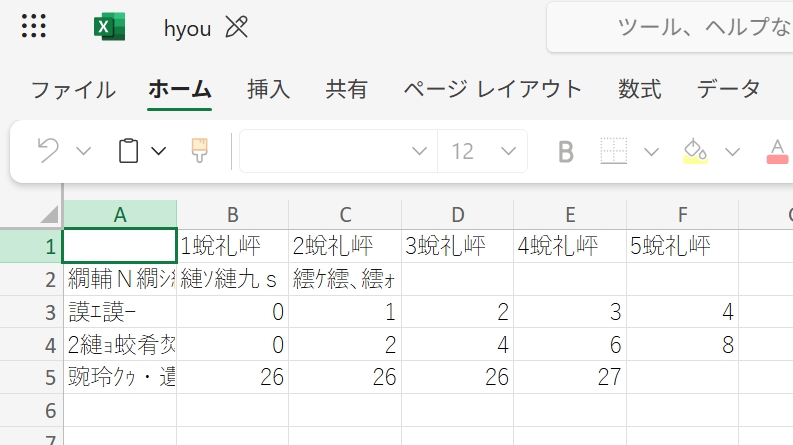
対策
encoding='utf_8_sig'をつけると文字化けしなくなります。
df1_new.to_csv("hyoubom.csv", encoding='utf_8_sig')この件は、こちら↓で解説しています。興味がありましたらご購入ください。

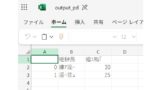
csvファイルから入力
今度は逆に今作ったcsvファイルをデータフレームに読み込みます。
コード
df1=pd.read_csv("hyou.csv")しかし読み込んだデータフレームを見ると保存したものとは
赤で囲った2か所が違ってます。
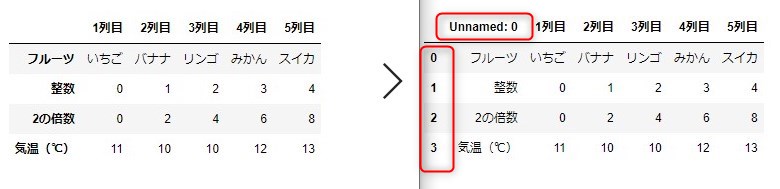
Unnamed:0はメモ帳でcsvファイルを見たときにあったように1番先頭が,から始まっているため
0,0の要素が何もないと判断されUnnamed:0が勝手に入れられています。
対策
df1=pd.read_csv("hyou.csv",index_col=0)0列目をインデックス列に指定して読み込めば解決します。

忘備録
やりがちなデータフレーム変換
忘備録として書いておきます。
list0=['時刻,0時,3時,6時,9時,12時,15時,18時,21時',
'天気,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ',
'気温(℃),2,2,2,5,7,7,4,5',
'湿度(%),31,33,34,25,23,24,39,39',
'降水量(mm),0,0,0,0,0,0,0,0']
df1=pd.DataFrame(data=list0)
df1うまくいきそうだがlist0は,で区切られてるだけ。
‘で囲われてる部分は
1個の要素なので1列の表になってしまう。
0
0 時刻,0時,3時,6時,9時,12時,15時,18時,21時
1 天気,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ,晴れ
2 気温(℃),2,2,2,5,7,7,4,5
3 湿度(%),31,33,34,25,23,24,39,39
4 降水量(mm),0,0,0,0,0,0,0,0下のようにするときれいにデータフレームが出来上がる。
#各要素を,で分割しリスト化
list1=list0[0].split(',')
list2=list0[1].split(',')
list3=list0[2].split(',')
list4=list0[3].split(',')
list5=list0[4].split(',')
list_all=[list2,list3,list4,list5]
list_all二次元のリストの形、個人的にこの形が扱いやすい。
[['天気', '晴れ', '晴れ', '晴れ', '晴れ', '晴れ', '晴れ', '晴れ', '晴れ'],
['気温(℃)', '2', '2', '2', '5', '7', '7', '4', '5'],
['湿度(%)', '31', '33', '34', '25', '23', '24', '39', '39'],
['降水量(mm)', '0', '0', '0', '0', '0', '0', '0', '0']]#list1をカラム、list2から5をデータにして表作成
df1=pd.DataFrame(data=list_all, columns = list1)
#インデックスが0123と数字になってしまうのでインデックスを時刻列にする
df1.set_index('時刻', inplace=True)
df1 0時 3時 6時 9時 12時 15時 18時 21時
時刻
天気 晴れ 晴れ 晴れ 晴れ 晴れ 晴れ 晴れ 晴れ
気温(℃) 2 2 2 5 7 7 4 5
湿度(%) 31 33 34 25 23 24 39 39
降水量(mm) 0 0 0 0 0 0 0 0inplace=True とインデックス
言葉の整理
「時刻 0時 3時 6時 9時 12時」は、カラム名(列ラベル)です。
「天気」「気温(℃)」「湿度(%)」は、インデックス(行ラベル)です。
inplace=Trueにするとインデックスに指定した列がindex列(行ラベル列)になります。
inplace=Trueをつけないと
インデックスに指定した列もデータとして扱うために
1列目にindex列(行ラベル列)として0123が追加されます。
inplace=True なしでcsvファイルを何回も読み書きしてると
そのたびに0123が追加されます。
また青色の見出し行が2行になるのも
インデックスとデータを切り分ける関係でこうなってると思います。
なのでこれは治らない。
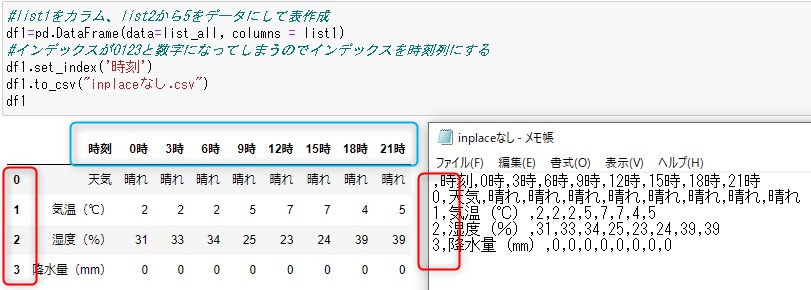
inplace なしとありで表示と書き出した時のcsvの違いを調べた。
inplace=True →見出し行が2行で表示される、csvは変わらない。
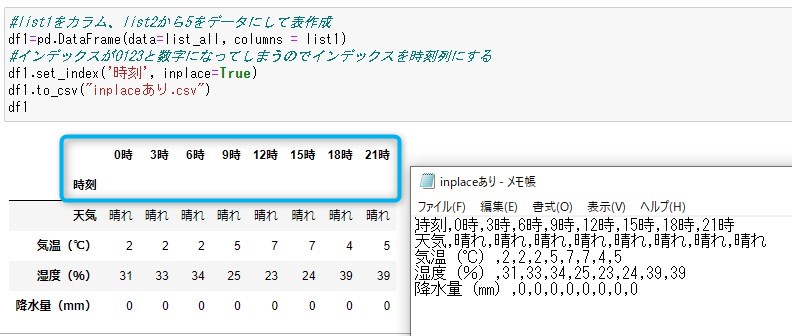
inplaceなし→見出し行は2行にならない。インデックス列に0123と数字が追加される。
見出し行を1列にしたい
最初のほうで作った果物とかの表はインデックス指定したのに
見出し行は1行です。
天気の表との違いはExcelでいう0,0の位置が空欄か文字が入っているかの違いです。
天気の表の見出し行を1行にするには
メモ帳で1番先頭の「時刻」を削除し,から始まるように変更すれば
1行になります。
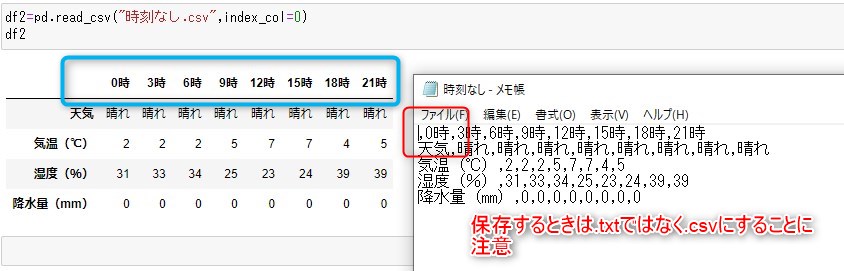
しかし表を作るとき以下のように先頭の要素を空欄にするとエラーになります。
list0=[',0時,3時,6時,9時,12時,15時,18時,21時',なのでリストで見出し行(columns)を指定するときは見出し行は2行になってしまう。
個人的には2行表示はカッコ悪いけどリストが扱いやすいので
2行表示は我慢してリストで作っていこうと思います。
1行にするには1番最後に紹介した方法もあるので。
この記事を書いたイチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
コメント