毎日どこかのサイトにいってデータを記録している場合、自動化できます。
具体例として神奈川県の感染者の件数を日付とともにコピペし
表(csvファイル)にまとめる方法です。
神奈川県の新型コロナウイルスに感染した患者の発生状況のデータを利用します。
2023/1/4ここで紹介するプログラムの動作確認はしていますが対象のページのフォーマットが変わった場合はうまくいきません。その場合、ご自分で修正してチャレンジしてみてください。
Windows10、JupiterNotebookを使用
GoogleColaboratoryでは
pyperclipなどのライブラリが使えないためエラーになります。
正規表現というものがあります。名前は難しいですが使えると便利です。紹介するプログラムは使っていませんが、文字を抽出するとき使うと便利です。いつまで無料かわかりませんがChatGPTで聞くと正規表現の例文を答えてくれます。以下参照。

別の方法です。
注意事項
アクセスするサーバーに負荷をかけないように
手動でアクセスするのと同じ回数、間隔で実行してください。
for文などを使った繰り返しによるアクセスはしないようにしてください。
コードを実行するときは自己責任でお願いします。
コードの内容を理解してから実行してください。
最前面のWindowが処理対象になるため処理中は他の操作はできません。
最前面にほかのWindowが出ていると、そのWindowに対して操作してしまいます。
動作画面
対象の画面構成が変わったため現在の動作とは違いますが、同じような動作をします。
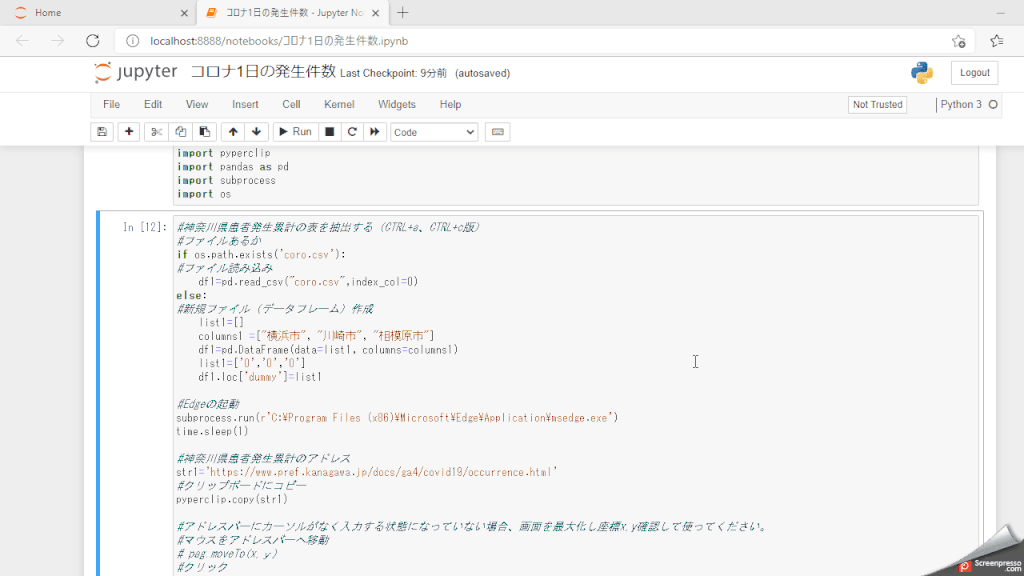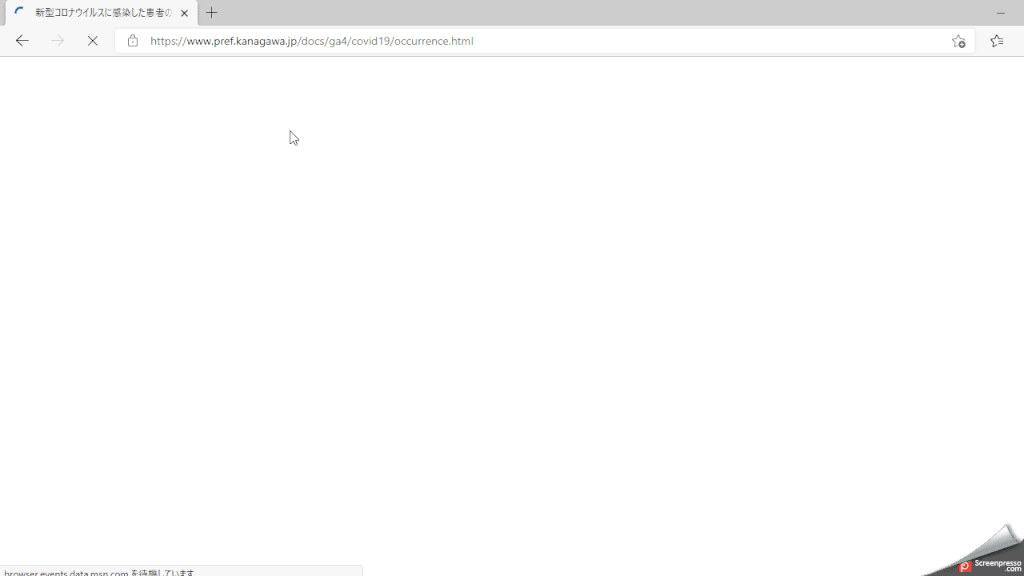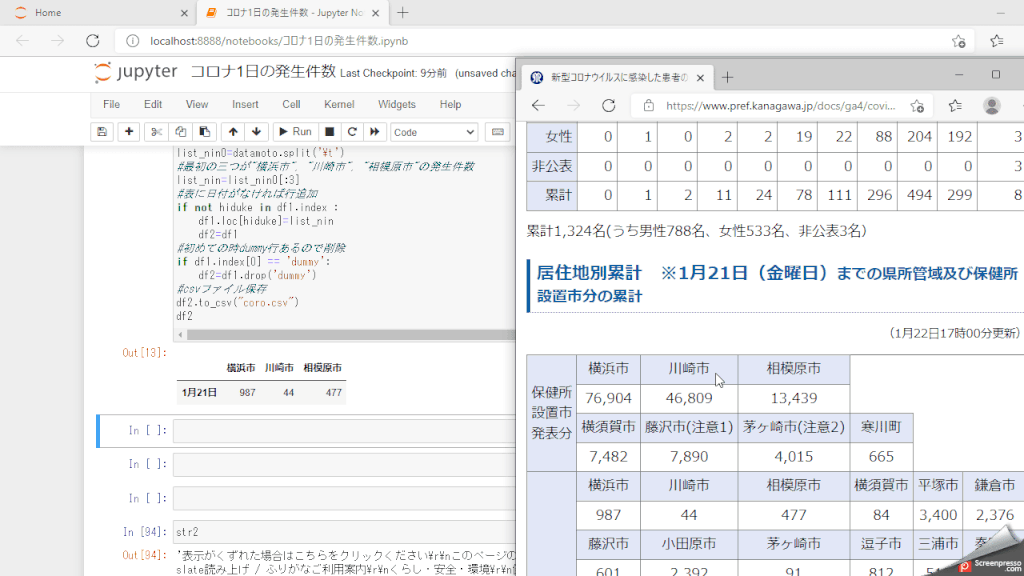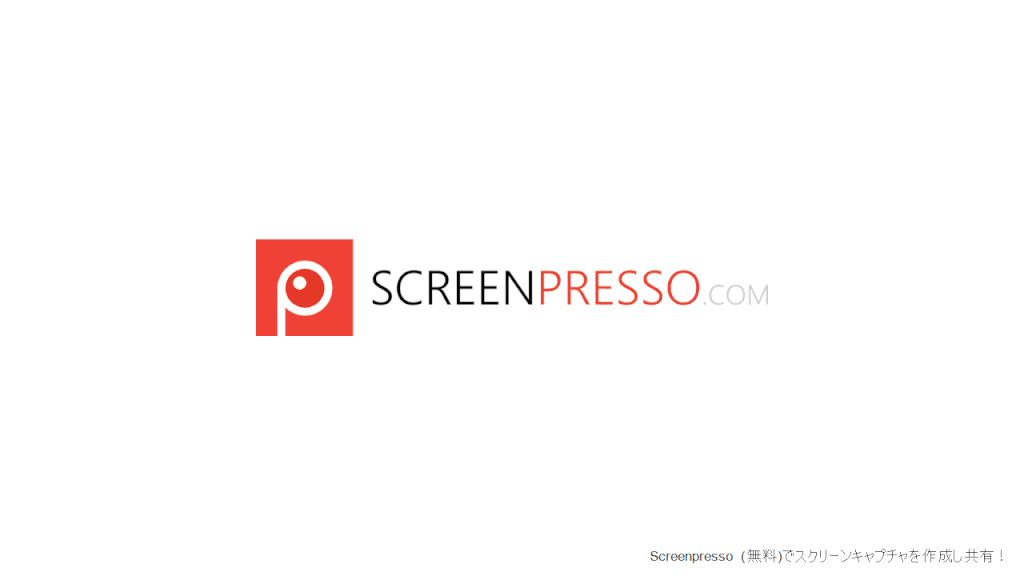
動作説明
神奈川県の 新型コロナウイルスに感染した患者の発生状況 にある患者等の状況から「入院患者」と「療養者」を表にします。
- ファイル(coro.csv)がある場合、読み込む。ファイルがない場合作成
- Edgeを起動し神奈川県患者発生状況のページへアクセス
- CTRL+a、CTRL+cで全部コピーして文字列変数に代入
- 日付、人数を抽出
- 表にしてcsvで保存(保存場所は作成しているプログラムと同じディレクトリになります)
大まかに抽出する
一気に抽出しないで、まずは大まかに抽出する。
抽出する方法は欲しいワードの前後唯一のワードを
replaceでbunkatu(なんでもいい)という文字に置き換えます。
その後spilitでbunkatuのところで分割する。
その結果リストになるので必要な要素のみ使用する。
全コピーしたものが入ってるstr2内の文字を探したり唯一かどうかを判定するのに
WindowsはF3キーを押すと文字検索できるので使ってください。
表などの場合、見た目とコピペした文字列の位置関係は関連性がないので
コピペした文字列から具体的な数字を目印に検索する。
元の画面を見て必要な情報
今回は「日付」と「入院患者」と「療養者」の前後の文字から
分割できそうな文字列を決める。
決める際、日によって変わらない不変なものを選ぶ。
例えば、10月3日を抽出するのに下の赤の部分を選ぶ。
症対策サイト\r\n\r\n患者等の状況\u300010月3日(月曜日)現在\r\n(10月4日17時
「月曜日の’月’」は日ごとに変わる部分で使えないので、そこの後ろを使う。
発生件数についてはコードの説明を見てください。
データを整える
大まかに抽出したあとは最終的な形にデータを整えます。
大まかに抽出したデータはhidukemoto=’10月3日(月’なので(で分割 hidukemoto1=hidukemoto.split(‘(‘)
分割するとhidukemoto1は[’10月3日’, ‘月’]というリストになるので
0番目の要素が最終的に欲しい日付 ’10月3日’ 。なので hiduke=hidukemoto1[0]
「入院患者」と「療養者」についてはコードの説明を見てください。
コード
コードです。
import pyautogui as pag
import time
import pyperclip
import pandas as pd
import subprocess
import os#神奈川県の入院患者、療養者患者の表を抽出する(CTRL+a、CTRL+c版)
#ファイルあるか
if os.path.exists('coro.csv'):
#ファイル読み込み
df1=pd.read_csv("coro.csv",index_col=0)
else:
#新規ファイル(データフレーム)作成
list1=[]
columns1 =["入院患者", "療養者"]
df1=pd.DataFrame(data=list1, columns=columns1)
list1=['0','0']
df1.loc['dummy']=list1
#Edgeの起動
subprocess.run(r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe')
time.sleep(1)
#神奈川県患者発生累計のアドレス
str1='https://www.pref.kanagawa.jp/docs/ga4/covid19/occurrence.html'
#クリップボードにコピー
pyperclip.copy(str1)
#アドレスバーにカーソルがなく入力する状態になっていない場合、画面を最大化し座標x,y確認して使ってください。
#マウスをアドレスバーへ移動
# pag.moveTo(x,y)
#クリック
# pag.click()
time.sleep(1)
#CTRL+Vで貼り付け
pag.hotkey("ctrl","v")
#Enter
pag.press('enter')
time.sleep(5)
#************ ctrl+aとCTRL+cで全部コピーしてstr2にペースト************
pag.hotkey("ctrl","a")
time.sleep(1)
pag.hotkey("ctrl","c")
time.sleep(1)
str2=pyperclip.paste()
time.sleep(2)
#Edgeを閉じる
pag.hotkey("Ctrl","w")
#日付を抽出するのに'患者等の状況\u3000'~'曜日)'現在までが大まかな対象なので分割の目印としてbunkatuを加える
#入院患者を抽出するのに'入院患者\t'~'\r\n \t重症'
#療養者を抽出するのに'療養者\t'~'\r\n \t宿泊施設療養'
str3=str2.replace('患者等の状況\u3000','bunkatu').replace('曜日)現在','bunkatu').replace('入院患者\t','bunkatu').replace('\r\n \t重症','bunkatu').replace('療養者\t','bunkatu').replace('\r\n \t宿泊施設療養','bunkatu')
#bunkatuで分割してリストへ
str4=str3.split('bunkatu')
#1番目の要素が日付の対象部分なのでstr4[1]使用
hidukemoto=str4[1]
#3番目の要素が入院患者の対象部分なのでstr4[3]使用
nyuuin0=str4[3]
#'\r\n'が不要なので削除(最初はなかった)
nyuuin=nyuuin0.replace('\r\n','')
#5番目の要素が療養者の対象部分なのでstr4[5]使用
ryouyou=str4[5]
#hidukemoto=1月21日(金曜日)なので(で分割
hidukemoto1=hidukemoto.split('(')
#0番目の要素が日付
hiduke=hidukemoto1[0]
#入院患者、療養者追加
list_nin=[]
list_nin.append(nyuuin)
list_nin.append(ryouyou)
#表に日付がなければ行追加
if not hiduke in df1.index :
df1.loc[hiduke]=list_nin
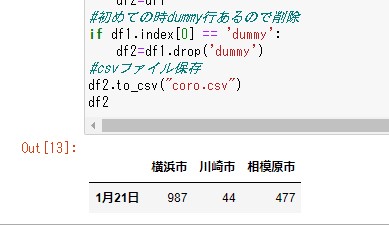
df2=df1
#初めての時dummy行あるので削除
if df1.index[0] == 'dummy':
df2=df1.drop('dummy')
#csvファイル保存
df2.to_csv("coro.csv")
df2目次へ
この記事を書いたイチゲを応援する
Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
コメント