無料のものだけ使ってます。
シーリングライトの取扱説明書のpdfをナレッジに使い、
それをもとに回答するチャットボットをつくってみます。
RAGを理解するのに言語モデルに何を入れているのかを
確認すると考えやすくなるので、そこを見ます。
DifyのChatflowでは、ログを表示できるので
各段階のデータが見れます。
ナレッジから引っ張ってくるデータと言語モデルに入れるデータを
具体的に見ることでRAGが理解しやすくなると思います。
Difyのナレッジのインデックス方法は経済的と高品質があります。
その比較も行います。
Difyクラウド版があれば確認できますが、
今回はローカルでやっているため言語モデルはGemini 1.5 Proを使います。
(2025/9/15追記)Gemini 1.5 は非推奨になっています。都度、情報は更新されますのでご注意ください。
https://ai.google.dev/gemini-api/docs/models?hl=ja#gemini-1.5-flash

また、ローカルでインデックス方法を高品質にする場合、埋め込みモデルも必要になりますので
Ollamaと埋め込みモデルが必要になります。(Difyクラウド版は、埋め込みモデルがついてる。)
私の勘違いで間違っていることを書いているかもしれないのでご了承ください。
Difyを立ち上げてからチャットフローを動かすまでの手順を書いていきます。
動いたら、ログを見てRAGの動きを確認していきます。
ナレッジ
ナレッジの目的はファイルなどをアップロードすれば、
そのファイルに関するチャットができるようにすることです。
手順
ナレッジ→知識を作成→テキストファイルをアップロードにpdfをドラッグアンドドロップ→次へ→インデックスモードを経済的→保存して処理
Tips
pdfは図をはさんだり自由なデザイン配置ができるため
読み込んでテキストのみになったら見た目と文字の位置が違う場合があります。
近くにあるはずの文字がかなり遠くにあり文章になっていない場合があります。
なのでpdfを別のツールを使ってテキストにして
手動で文章を整えたテキストファイルを使ったほうがいいかもしれません。
目次へ
チャットフロー
チャットボットは「基本」を使うより「チャットフロー」を使う方が動きが見えるのでおすすめです。
なので今回はチャットフローを使います。
手順
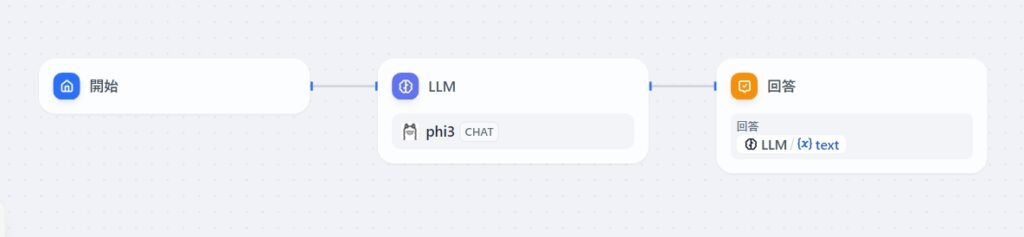
スタジオ→チャットボット→最初から作成→「チャットボットのオーケストレーション方法」をChatflowにします。→「アプリのアイコンと名前」に適当な名前を付けます。→作成すると以下のようにflowが出来上がる。
LLMのモデルがphi3Chatとなっているが後でGemini 1.5 Proに変えます。
この図はプログラムのコードを図式化したようなもになっています。
まずチャットの入力欄にユーザーが入力した質問が
開始ブロックの{x}sys.queryという変数に入ります。
その変数をLLMに渡し、LLMの返答が{x}textに入ります。
最後に回答のところで{x}textをチャットの返答として表示します。
目次へ
知識取得の追加
追加する「知識の取得」ブロックは質問を入力すると
ナレッジから答えが書かれていると思われるテキストチャンク(段落)を抽出し
{x}resultに入れます。
手順
開始とLLMの間の線にマウスを持っていくと+が表示されるのでクリック
知識取得→知識の横にある+をクリックして「参照する知識を選択」で先ほど作ったナレッジをクリックします。→追加
目次へ
LLM修正
LLMは質問(クエリ)をLLMに投げるところです。
デフォルトの状態では質問しかLLMに渡りませんが
直前に追加した「知識取得」の出力{x}result(テキストチャンク)もLLMになげるようにします。
LLMをクリック→モデルの∨をクリックして開いた画面のModelをGemini 1.5 Proに変えます。
コンテキストをクリックして「知識取得」にある{x}resultをクリック
SYSTEMの欄に「あなたはシーリングライトのお問い合わせ担当です。以下を参考に回答してください。」と入力し{x}をクリック→1番上のコンテキストをクリック
質問はどこにあるかというとuserに{x}sys.queryとあります。
これがチャット欄で入力した値で「開始」ブロックで変数{x}sys.queryに入力されます。
その値がデフォルトでLLMのuserに入っています。
後で確認しますが、このsys.queryと
「知識取得」で抽出した{x}result(テキストチャンク)がLLMに投げられています。
目次へ
デバッグ
デバッグとプレビューをクリックするとチャットボットが動きます。
チャット欄に質問を入力します。
例「電源の入れ方を教えて」
その結果、恐らく期待したようなナレッジベースの回答ではなく
一般的な回答になっていると思います。(つまりナレッジを見てない)
原因を調査します。
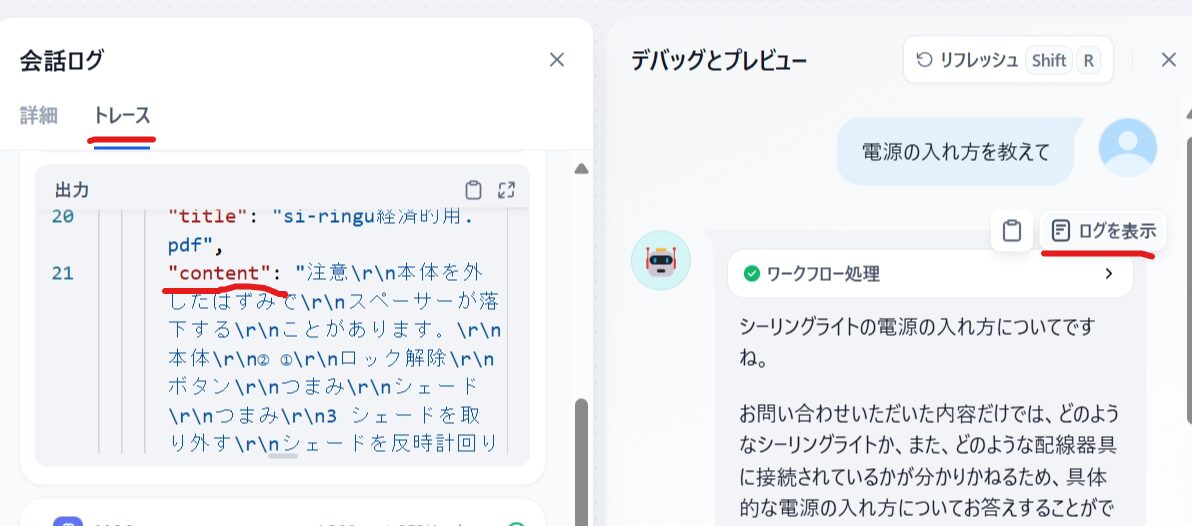
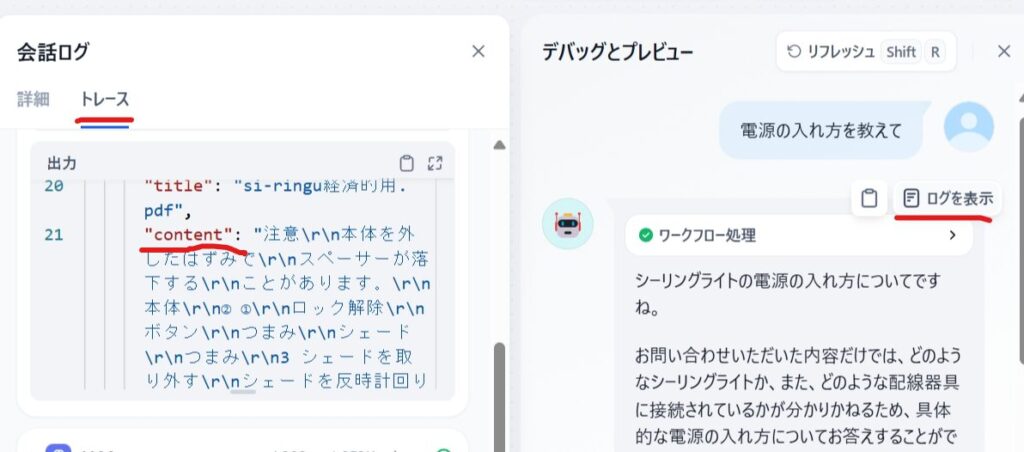
下図のように「ログを表示」があるのでクリックすると左側の画面が出ます。
トレースタグの知識取得(下図では隠れている)を開きます。
出力のcotententに知識取得から引っ張ってきた文章が見れます。
これを見ると質問の「電源の入れ方を教えて」に対して、答えられるような内容が抽出されてません。
なのでLLMは答えられなかったと思います。
また今回は何かしら抽出されていますが、うまくいかないときは
“result”: []となって空っぽのときがあります。
LLMのデータ処理
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
続いて、トレースのLLMをクリックして開くと「データ処理」というところがあります。
これが実際にLLMに入力されるプロンプトだと思われます。
赤線の部分が知識取得から引っ張ってきた文章になっています。
青線がsys.query(ユーザーがチャット欄に質問した内容)になります。
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "あなたはシーリングライトのお問い合わせ担当です。以下を参考に回答してください。注意\r\n本体を外したはずみで\r\nスペーサーが落下する\r\nことがあります。\r\n本体\r\n② ①\r\nロック解除\r\nボタン\r\nつまみ\r\nシェード\r\nつまみ\r\n3 シェードを取り外す\r\nシェードを反時計回り***略****変形•火災の原因になります",
"files": []
},
{
"role": "user",
"text": "電源の入れ方を教えて",
"files": []
}
]
}この文(トレースのLLMをクリックして開いた「データ処理」の文)を
そのままコピーしてChatGPTやBing、Geminiなどブラウザで
無料で実行できる言語モデルの生成AIに入れても同じような答えが返ってくると思います。
{}などはjson形式ですが、これは通信電文としてうまくやり取りできるようについているだけで
実際に言語モデルに入るときは意味を持たない部分だと思います。
うまく答えられていない原因は知識取得が質問内容と違うところを抽出しているからでした。
「知識取得」ブロックが取得しやすいように質問文を変えてみます。
具体的には、ベースの文章で答えのもとになってほしい
フレーズを少し変形して質問するとうまく引っ張って来れます。
「壁スイッチで明かりをつける」という文章がベースのpdfの中にあるので
質問を「壁スイッチで操作して明かりをつけるには」に変えるとうまく答えます。
目次へ
ナレッジのインデックスモードを変えて知識取得できるようにする
ナレッジでやっていること
ナレッジでやっていることは、
参照するテキスト文章をテキストチャンクという段落に分割しています。
ナレッジの目的は、ユーザーの質問に対して参照するべきテキストチャンクを選ぶことです。
その方法はテキストをある単位(例えば単語)で分割し、
分割した単語をベクトルに割り付けます。これがインデクスで。
インデクスはベクトルになっていて、
そのベクトルにすることをベクトル空間に埋め込むと言ってるのだと思います。
この埋め込みの話は、こちらのYoutube(該当箇所にリンクしてる)がおすすめです。
ただ「知識取得」でやっているのは埋め込みを利用しているだけで
動画のようにLLMに埋め込んでいるわけではありません。
あくまで文字をベクトル空間に埋め込むイメージの例としてあげただけです。
ベクトルによって質問のベクトル群とナレッジのチャンク内のベクトル群を
比較(内積を使う)することによって、
どのチャンクが1番、質問に近い内容か探せるのだと思います。
ここの検索処理はモデルは使っていないようなのでプログラムだと思います。(再ランクは除く)
この一連の単位(単語など)に分割するのとベクトルに割り付ける手法が様々で
この手法の良しあしで、質問に対するテキストチャンクの抽出能力に効いてくるのだと思います。
前項でみたように、インデクス手法を「経済的」にしてると
質問に対するテキストチャンクが的確に選ばれていませんでした。
質問を元の文章で使われている表現からあまり変わらにようにすると
的確に選ばれています。
といことから経済的の能力は単純にWordやメモ帳などで使う単語検索に
毛が生えた程度の能力だと思います。
それに対し埋め込みモデルを使用した高品質なインデクス方法では
質問の文意と各チャンクテキストの文意が比較できるような検索能力を備えているのだと思います。
さらに検索設定で再ランクモデルというのを使用できるようになっています。
再ランクモデルは有料なものしか見つからなかったので試していませんが
これを使ったらさらに良くなりそうです。
この段階では質問に対する答えの元となるテキストチャンク(段落)を選んでいるだけで
LLMの処理とは関係ない段階であることを知ると、RAGが考えやすいと思います。
目次へ
インデクス方法を高品質に変更
ここは埋め込みモデルが必要になります。
私はOllamaとmxbai-embed-largeのインストールを使用しています。
これは無料でローカルで使用できます。
同じ名前のファイルだとうまくいかなかったので
同じpdfを名前を変えてアップロードします。
ナレッジ→知識を作成→テキストファイルをアップロードにpdfをドラッグアンドドロップ→次へ→インデックスモードを高品質→検索設定をベクトル検索
保存して処理
知識取得をクリック→知識にあるものを削除→+で今、作ったナレッジを追加します。
先ほどうまくいかなかった質問「電源の入れ方を教えて」をしてみます。
そうすると知識取得で、さっきとは違う箇所が抽出されてナレッジにそった回答をしてくれます。
目次へ
個人的メモ(よく調べていないので間違っています。)
systemとuserはユーザーが指定するもの
systemは言語モデルに役割などの指示を書く。userは質問。
assistantは’言語モデルが生成した応答を指しますが、一般的にユーザーがプロンプトで指定することも可能です。この場合、ユーザーが自身の期待する応答の例を提供し、モデルに対してそのスタイルや内容を示唆することができます。’(ChatGpt談)
system、user、assistantは、プロンプトに書くが、そういう仕様は、別に存在しないと思う。
経験的な話で、こうするとうまく回答してくれる傾向だという話ではないか。
課金される場合、トークンは入力と回答を足したものに課金される。
入力のプロンプト(system、user、assistant)と言語モデルの回答(assistant)はコンテキスト内に貯められコンテキストサイズに達すると最初のほうが削除されるか要約される。
新しいチャット操作をするとコンテキストはクリアされる。
まとめ
Chatflowを使うとトレースによって、やり取りしているデータが具体的に見れるので
しくみの理解や対策を立てるのに役立ちます。
ナッレジにしたい文章全部と質問をLLMにそのまま入れるのが
1番うまく回答してくれるのではないかと思います。
しかしAPIを使う場合、トークン数が膨大になってしまいます。
なのでトークン数の節約がRAGの目的のひとつだと思います。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)