StreamlitはPythonで作ったものを比較的簡単にWebで公開できます。
どんなものが作れるかご紹介です。
私が思う限界も指摘しておきます。
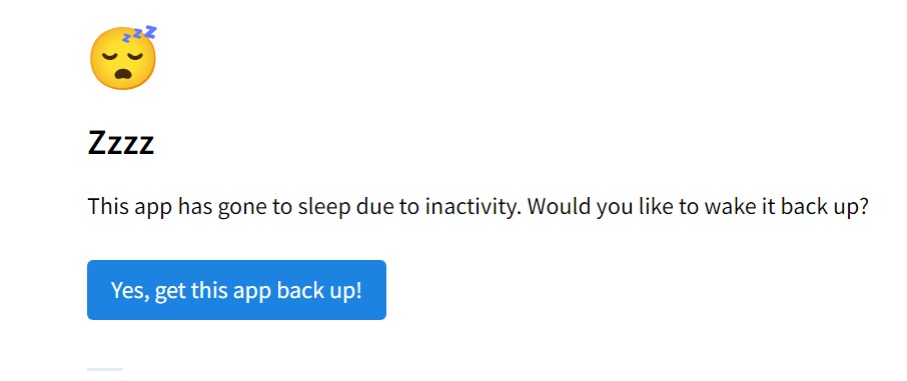
作ったアプリは下にありますが、アクセスするとほとんどの場合
この画面になってアプリが寝てる状態になります。
(無料プランなのでアクセスがしばらくないとスリープするため)
「Yes,get this app back up!」をクリックしてしばらくすると動き出します。
1、2つのAPIにrequestsで送受信して声の出る天気予報アプリ。
ずんだもんの声で天気を教えてくれるよ!
2、掲示板アプリ。投稿内容をcsvに保存しています。
csvファイルに保存する掲示板
3、機械学習ライブラリscikit-learnを使ったあやめの分類
scikit-learnを使って予測
4、掲示板アプリ。投稿内容をsqlite3に保存します。
掲示板(Sqlite3) – イチゲブログ
5、グラフ表示
イチゲブログ、イチゲブログ別館2階のアクセス数(Cocoon集計値)
思いついたら追加していきます。
他に作ったもの一覧
2026/3/2 【不具合発生】Hmm… looks like it’s taking longer than normal.Check back in a minute or two!原因と対策は↓↓

ずんだもんの声で天気を教えてくれるよ!
ずんだもんの声で天気を教えてくれるよ!
ChatGPTなどのAPIとつなげてみたいところですが、有料なので無料のお天気サイトを利用しました。
処理概要
- 天気を知りたいところの県名を含んだ質問文を入力
- 県名を送ると天気予報が返ってくるAPIサイトにrequestsでアクセス
- レスポンスを処理して天気予報の22文字を取り出す。(長いと音声変換に時間がかかるため)
- 取り出した文章をずんだもんの声に変換してくれるAPIサイトにrequestsでアクセス
- mp3ファイルをダウンロードして再生
文字の入出力部分はStreamlitのChat elementsを使用
音声再生に関してはこちらを参考にさせていただきました。
Streamlitで音声ファイルを自動再生する方法
天気予報とずんだもんの声のAPIについては、こちらを参照してください。

csvファイルに保存する掲示板
csvファイルに保存する掲示板
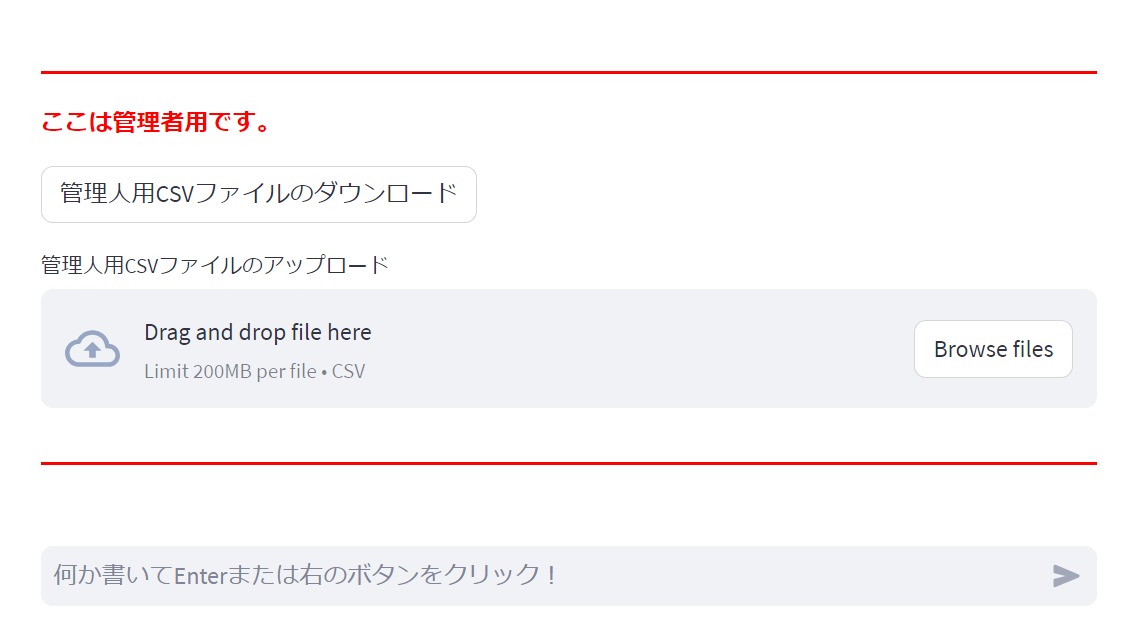
掲示板で投稿されたデータをcsvファイルに保存して運用するようにしました。
アプリがスリーブしてリブートが必要になったときgithubに保存したデフォルトのcsvに戻ってしまいます。そうなると投稿は全部消えてしまうので、いつでもバックアップが取れるようにcsvファイルをダウンロードできるようにしました。
また、アップロードすれば投稿内容を戻せるようにしてます。
csvファイルのダウンロード、アップロードはStreamlitでは簡単に実装できます。
ダウンロード
# CSVファイルをダウンロードするボタンを追加
st.download_button(
label="管理人用CSVファイルのダウンロード",
data=df.to_csv().encode('utf-8'), # データフレームをCSV形式に変換してエンコード
file_name='toukou.csv', # ダウンロードするファイル名を指定
key='download-button'
)アップロード
# CSVファイルをアップロードするウィジェットを追加
uploaded_file = st.file_uploader("管理人用CSVファイルのアップロード", type=["csv"])
if uploaded_file is not None:
# アップロードされたファイルをデータフレームに読み込む
df7 = pd.read_csv(uploaded_file,index_col=0)
#データフレームをファイルに保存
df7.to_csv("toukou.csv")Streamlit Cloudに保存したcsvファイルは以下でデータフレームに変換できます。
df=pd.read_csv("toukou.csv",index_col=0)toukou.csvのデフォルト中身
,投稿日,内容
0,2023年09月06日 13:20:28,管理人-ご自由に書き込みください。複数人が同時にアクセスしたときなどファイルの不整合が起きると思うので
下のSQLite3に保存する掲示板ほうがいいと思います。
scikit-learnを使って予測
scikit-learnを使って予測
scikit-learnの処理はこちらのYoutubeを参考にさせていただきました。【Pythonプログラミング】scikit-learnで機械学習!〜 入門編・初心者向け 〜
機械学習について疑問がでてくるとこで情報が少ないと思うのが、どうやって使うかというところです。
つまり
・知りたい「特徴量のセット」をどうやって入力するか。
・出力結果はどうやって得られるか。
実装するために行ったことを説明します。
入出力処理
scikit-learnで予測している処理
pred=clf.predict(X_test)
の入力しているX_testの中身を見ると以下
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm
82 5.8 2.7 3.9 1.2
複数行続くが略
出力のpredは
['Iris-versicolor' 'Iris-versicolor' ・・・
よって
入力-知りたい特徴量のセット1つでデータフレームを作る。IDは適当でいい。
出力-predの1個目具体的には以下の処理でStreamlitで実現できる。
with st.form(key='profile_form'):
test_input=st.text_input('特徴量を4つ,区切りで入力してください。例、4.6,3.1,1.5,0.2')
submit_btn=st.form_submit_button('予測表示')
if test_input:
ayame_list_input=test_input.split(',')
data = {
'Id': [1],
'SepalLengthCm': ayame_list_input[0],
'SepalWidthCm': ayame_list_input[1],
'PetalLengthCm': ayame_list_input[2],
'PetalWidthCm': ayame_list_input[3],
}
ask = pd.DataFrame(data).drop(['Id'], axis=1)
predicted=clf.predict(ask)
if submit_btn:
st.write(f'種類予測: {predicted[0]}')任意の学習データを使う
任意の学習データをアップロードできるようにしました。
学習データの例として
あやめの分類Iris.csvの項目とSpecies欄を以下のように変更。さらに各数を30個に減らした。
Id,SepalLengthCm,SepalWidthCm,PetalLengthCm,PetalWidthCm,Species
→Id,koumoku1,koumoku2,koumoku3,koumoku4,bunrui
Speciesの欄を
setosa→セトサ、versicolor→バージカラー)、virginica→バージニカ
以下のコードをcsvとして保存してアップロードしてみてください。
具体的にはWindowsの場合、
メモ帳を立ち上げます→下記コードに公式のサンプルプログラムをコピペ
→メモ帳のファイル→名前を付けて保存
→「ファイルの種類」をテキスト文章ではなく、すべてのファイルに変更(ここが大事です)
→任意のファイル名(例test.csv)→保存Id,koumoku1,koumoku2,koumoku3,koumoku4,bunrui
1,5.1,3.5,1.4,0.2,セトサ
2,4.9,3.0,1.4,0.2,セトサ
3,4.7,3.2,1.3,0.2,セトサ
4,4.6,3.1,1.5,0.2,セトサ
5,5.0,3.6,1.4,0.2,セトサ
6,5.4,3.9,1.7,0.4,セトサ
7,4.6,3.4,1.4,0.3,セトサ
8,5.0,3.4,1.5,0.2,セトサ
9,4.4,2.9,1.4,0.2,セトサ
10,4.9,3.1,1.5,0.1,セトサ
11,5.4,3.7,1.5,0.2,セトサ
12,4.8,3.4,1.6,0.2,セトサ
13,4.8,3.0,1.4,0.1,セトサ
14,4.3,3.0,1.1,0.1,セトサ
15,5.8,4.0,1.2,0.2,セトサ
16,5.7,4.4,1.5,0.4,セトサ
17,5.4,3.9,1.3,0.4,セトサ
18,5.1,3.5,1.4,0.3,セトサ
19,5.7,3.8,1.7,0.3,セトサ
20,5.1,3.8,1.5,0.3,セトサ
21,5.4,3.4,1.7,0.2,セトサ
22,5.1,3.7,1.5,0.4,セトサ
23,4.6,3.6,1.0,0.2,セトサ
24,5.1,3.3,1.7,0.5,セトサ
25,4.8,3.4,1.9,0.2,セトサ
26,5.0,3.0,1.6,0.2,セトサ
27,5.0,3.4,1.6,0.4,セトサ
28,5.2,3.5,1.5,0.2,セトサ
29,5.2,3.4,1.4,0.2,セトサ
30,4.7,3.2,1.6,0.2,セトサ
51,7.0,3.2,4.7,1.4,バージカラー
52,6.4,3.2,4.5,1.5,バージカラー
53,6.9,3.1,4.9,1.5,バージカラー
54,5.5,2.3,4.0,1.3,バージカラー
55,6.5,2.8,4.6,1.5,バージカラー
56,5.7,2.8,4.5,1.3,バージカラー
57,6.3,3.3,4.7,1.6,バージカラー
58,4.9,2.4,3.3,1.0,バージカラー
59,6.6,2.9,4.6,1.3,バージカラー
60,5.2,2.7,3.9,1.4,バージカラー
61,5.0,2.0,3.5,1.0,バージカラー
62,5.9,3.0,4.2,1.5,バージカラー
63,6.0,2.2,4.0,1.0,バージカラー
64,6.1,2.9,4.7,1.4,バージカラー
65,5.6,2.9,3.6,1.3,バージカラー
66,6.7,3.1,4.4,1.4,バージカラー
67,5.6,3.0,4.5,1.5,バージカラー
68,5.8,2.7,4.1,1.0,バージカラー
69,6.2,2.2,4.5,1.5,バージカラー
70,5.6,2.5,3.9,1.1,バージカラー
71,5.9,3.2,4.8,1.8,バージカラー
72,6.1,2.8,4.0,1.3,バージカラー
73,6.3,2.5,4.9,1.5,バージカラー
74,6.1,2.8,4.7,1.2,バージカラー
75,6.4,2.9,4.3,1.3,バージカラー
76,6.6,3.0,4.4,1.4,バージカラー
77,6.8,2.8,4.8,1.4,バージカラー
78,6.7,3.0,5.0,1.7,バージカラー
79,6.0,2.9,4.5,1.5,バージカラー
80,5.7,2.6,3.5,1.0,バージカラー
101,6.3,3.3,6.0,2.5,バージニカ
102,5.8,2.7,5.1,1.9,バージニカ
103,7.1,3.0,5.9,2.1,バージニカ
104,6.3,2.9,5.6,1.8,バージニカ
105,6.5,3.0,5.8,2.2,バージニカ
106,7.6,3.0,6.6,2.1,バージニカ
107,4.9,2.5,4.5,1.7,バージニカ
108,7.3,2.9,6.3,1.8,バージニカ
109,6.7,2.5,5.8,1.8,バージニカ
110,7.2,3.6,6.1,2.5,バージニカ
111,6.5,3.2,5.1,2.0,バージニカ
112,6.4,2.7,5.3,1.9,バージニカ
113,6.8,3.0,5.5,2.1,バージニカ
114,5.7,2.5,5.0,2.0,バージニカ
115,5.8,2.8,5.1,2.4,バージニカ
116,6.4,3.2,5.3,2.3,バージニカ
117,6.5,3.0,5.5,1.8,バージニカ
118,7.7,3.8,6.7,2.2,バージニカ
119,7.7,2.6,6.9,2.3,バージニカ
120,6.0,2.2,5.0,1.5,バージニカ
121,6.9,3.2,5.7,2.3,バージニカ
122,5.6,2.8,4.9,2.0,バージニカ
123,7.7,2.8,6.7,2.0,バージニカ
124,6.3,2.7,4.9,1.8,バージニカ
125,6.7,3.3,5.7,2.1,バージニカ
126,7.2,3.2,6.0,1.8,バージニカ
127,6.2,2.8,4.8,1.8,バージニカ
128,6.1,3.0,4.9,1.8,バージニカ
129,6.4,2.8,5.6,2.1,バージニカ
130,7.2,3.0,5.8,1.6,バージニカ
「予測したいデータ」は削除したデータの中から選んで実験してみてください。
例えばID99の以下をコピペ
5.1,2.5,3.0,1.1
種類予測: バージカラーになるはずです。(機械学習なので100%正解するとは限らない)
このようにあやめの分類の学習データのフォーマットをベースに任意の学習データをつくれば
scikit-learnが実用できると思います。
目次へSQLite3に保存する掲示板
「csvファイルに保存する掲示板」をベースにSQLite3で保存するようにしました。
アプリがスリーブしてリブートが必要になったとき、全部消えるので
データの入っているmain.dbファイルをダウンロード、アップロードできるようにしました。
import streamlit as st
import pandas as pd
import datetime
import sqlite3
import os
class Database:
def __init__(self,_dbname='main.db'):
self.dbname = _dbname
if os.path.isfile(self.dbname) != True:
self.create_bd()
self.create_table()
def create_bd(self):
conn = sqlite3.connect(self.dbname)
conn.close()
def create_table(self):
conn = sqlite3.connect(self.dbname)
cur = conn.cursor()
cur.execute('CREATE TABLE users(id INTEGER PRIMARY KEY AUTOINCREMENT, name STRING, message STRING)')
conn.close()
def write_data(self,_name,_message):
conn = sqlite3.connect(self.dbname)
cur = conn.cursor()
cur.execute(f'INSERT INTO users(name,message) values("{_name}", "{_message}")')
conn.commit()
conn.close()
def read_data(self):
conn = sqlite3.connect(self.dbname)
cur = conn.cursor()
cur.execute('SELECT * FROM users')
data = cur.fetchall()
conn.close()
return data
def delete(self, id):
conn = sqlite3.connect(self.dbname)
cur = conn.cursor()
cur.execute(f'DELETE FROM users WHERE id = {id}')
conn.commit()
conn.close()
db = Database()
st.title('掲示板(Sqlite3) - イチゲブログ')
st.caption('最下部の入力欄に書いてEnterしてください。削除も可能です。')
st.markdown('###### Streamelitやこのサイトの関連情報は')
link = '[イチゲブログ](https://kikuichige.com/21772/)'
prompt=st.chat_input("何か書いてEnterまたは右のボタンをクリック!")
st.markdown(link, unsafe_allow_html=True)
del_list=[]
for x in db.read_data():
# 水平線を表示
st.markdown("<hr>", unsafe_allow_html=True)
st.write(str(x[0]),'番')
st.write(' 日付:',str(x[1]))
st.write(' 内容:',str(x[2]))
del_list.append(x[0])
if prompt:
# 水平線を表示
st.markdown("<hr>", unsafe_allow_html=True)
message1 = st.chat_message("user")
message1.write(f"内容:{prompt}")
t_delta = datetime.timedelta(hours=9) # 9時間
JST = datetime.timezone(t_delta, 'JST') # UTCから9時間差の「JST」タイムゾーン
dt_now = datetime.datetime.now(JST) # タイムゾーン付きでローカルな日付と時刻を取得
toukoubi=dt_now.strftime('%Y年%m月%d日 %H:%M:%S')
db.write_data(toukoubi,prompt)
# 水平線を表示
st.markdown("<hr>", unsafe_allow_html=True)
with st.form(key='keijiban_form'):
del_no=st.selectbox(
'削除する番号を選んでください',
(del_list))
del_btn=st.form_submit_button('削除')
if del_btn:
db.delete(del_no)
text='<span style="color:red">表示更新を押してください!</span>'
st.write(text, unsafe_allow_html=True)
# カスタムCSSスタイルを定義
custom_css = """
<style>
hr {
border: none;
border-top: 2px solid red;
margin: 20px 0;
}
.red-bold {
color: red;
font-weight: bold;
}
</style>
"""
# カスタムCSSスタイルを適用
st.markdown(custom_css, unsafe_allow_html=True)
# 水平線を表示
st.markdown("<hr>", unsafe_allow_html=True)
# 赤い太字の文字を表示
st.markdown("<span class='red-bold'>ここは管理者用です。</span>", unsafe_allow_html=True)
# 水平線の下にコンテンツを追加
# st.write("ここは水平線の下に表示されるコンテンツです。")
# dbファイルをダウンロードするボタンを追加
with open("main.db", "rb") as file:
st.download_button(
label="管理人用dbファイルのダウンロード",
data=file,
file_name='main.db', # ダウンロードするファイル名を指定
key='download-button'
)
# dbファイルをアップロードするウィジェットを追加
uploaded_file = st.file_uploader("管理人用dbファイルのアップロード", type=["db"])
# main.dbのファイルパス
main_db_name = "main.db"
# アップロードされたファイルをmain.dbに上書き
if uploaded_file:
with open(main_db_name, "wb") as f:
f.write(uploaded_file.read())
st.success("main.dbファイルを上書きしました。")
st.markdown("<hr>", unsafe_allow_html=True)
Streamlitを使う上での個人的感想など
あくまで個人的に使っての感想です。Streamlitでは本格的なアプリは無理ではないかと思います。
フロントとバックエンド
フロントとバックエンドが分かれていないのは簡単に作れていいが、
何かアクションを起こすとリロードして、多分、冒頭から処理が走っているので扱いずらいです。
Html+Javascriptのフロントエンドだけで同じようなことができるとおもいますが、
複雑な処理はJavascriptよりPythonのほうが、わかりやすいので、そこはメリットです。
しかしStreamlit+pythonだけで何とか頑張っても限界がありそうです。
バックエンド側をDjango(Python)、フロント側をHtml+Javascriptなどで作ったものと比較すると
フロント、バックエンドともに自由度が全然違います。
その辺の折り合いをつけてStreamlitにするかバックエンド、フロントエンドのシステムにするか選ぶ感じですね。
実行するとブラウザに「英語のページを翻訳しますか?」と出る
これはStreamlitで実行され表示されるhtmlが<html lang=”en”>(英語)になっているためで
<html lang=”ja”>(日本語)に変えればでなくなるはずです。
この件の解決策をChatGPTに聞いてみると
st._container.htmlで現在のhtmlを取得して書き換える方法が答えで返ってきたました。
でも私は、試してはいないです。
うまくいくかわからないしStreamlitがバージョンアップすると使えない方法かもしれない。
とりあえずブラザの設定で、翻訳を表示させなければ済みます。
Edgeの場合、設定→言語→「自分が読み取ることができない言語のページの翻訳を提案する」をOFF
処理的に問題なければ・・・
Streamlit特有の問題でエラーが画面に表示してしまう場合、最終手段としてtry、exceptで以下のようにしてごまかす方法もある。
エラー発生時はexceptが実行されるので何もしないpassにする。
try:
エラーが発生する処理
except:
pass所感
簡単にいろいろなことができてしまうので、分からないことがあると部分的な解決策に走ってしまう。
なので動作原理的なところの理解をおろそかにしてしまう。
その結果できることとできないことの判別が難しくなってしまった。
改めてStreamlitの基本の理解が必要だと思った。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
コメント