文字列などをSQLite3に保存するとdb.sqliteファイルに保存される。mp3も同じようにdb.sqliteに保存されるのか?と予想していましたが。mp3を実際に保存してみるとmanage.pyが置いてあるルートのディレクトリにmp3ファイルとして保存されました。ずんだもんのmp3を動的に保存するアプリを作って確認しました。
作ったアプリがこちら
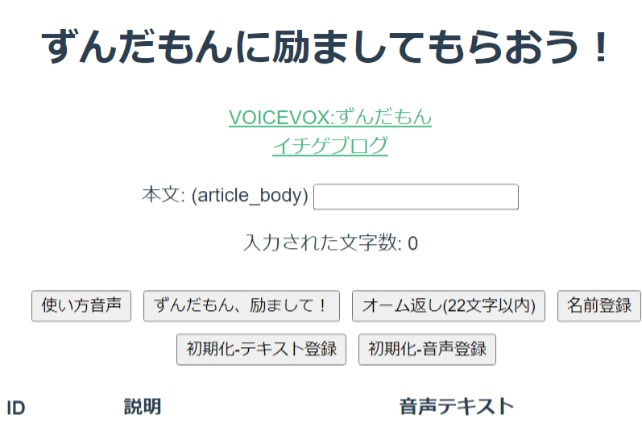
ずんだもんに励ましてもらおう!+ずんだもんに天気を聞いてみよう!(お名前.comVPSにデプロイ)(2026/4/28メモリ節約のため停止)
ずんだもんに励ましてもらおう!+ずんだもんに天気を聞いてみよう!(Renderにデプロイ立ち上がるまで数分かかります)
Renderの無料プランにデプロイしているので立ち上がるまで数分かかります。
またデータベースのデータが毎回なくなるので、
最初にmp3を持ってきて保存するのに50秒かります。
使い方は下を見てください。
2025/6/24追記(Claudeで作り直してCursorでさらに修正しました。)
新ずんだもんに励ましてもらおう!+ずんだもんに天気を聞いてみよう!(お名前.comVPSにデプロイ)
音声入出力は、これ↓が簡単です。

Renderの無料プランについてはこちらの記事を参考にしてください。
ずんだもんのmp3についてはこちらの記事を参考にしてください。
アプリのベースにしたのは、こちらのDjangoのRestFrameworksとVue.jsで作ったアプリです。
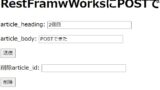
mp3を動的に保存してみた
テキストに対するずんだもんの声のmp3を取得しています。ずんだもんの声のmp3を動的に取得する方法参照
situmon='お疲れーっす。ずんだもんです。'
url=r'https://api.tts.quest/v1/voicevox/?text='+urllib.parse.quote(situmon)+r'&speaker=1'
res = requests.get(url)
time.sleep(5)
d=res.json()
song=d["mp3DownloadUrl"]songにはmp3があるurlが入っています。ChatGptに、どうやって保存すればいいか聞いた結果。
response = urllib.request.urlopen(song)
#responseはhttp.client.HTTPResponse object
#http.client.HTTPResponse オブジェクトは、Python の http.client モジュールによって提供される HTTP レスポンスオブジェクトです。HTTP サーバから受け取った HTTP レスポンスを表します。このオブジェクトには、ステータスコード、ヘッダー、本文など、HTTP レスポンスに関する情報が含まれています。
# レスポンスオブジェクトからファイルオブジェクトを作成します。
from django.core.files.base import ContentFile
file_obj = ContentFile(response.read(), name='my_song.mp3')
# ファイルオブジェクトをモデルに保存します。
song = Song()
song.title='モアちゃん'
song.audio_file = file_obj
song.save()
保存するモデルmodels.py
class Song(models.Model):
song_id = models.AutoField(primary_key=True)
title = models.CharField(max_length=64)
audio_file = models.FileField()
保存されたものをDjango REST frameworkのApi画面で見てみると以下のようになっています。
"audio_file"には保存先が保存され、実際のmp3ファイルはルート(manage.pyがあるディレクトリ)に保存されています。
{
"song_id": 1,
"title": "モアちゃん",
"audio_file": "https://zundahage.onrender.com/my_song_GH087BQ.mp3",
},
目次へフロントから読み出して音を鳴らす
フロント側(Vue.js)
フロント側のJavascriptは以下の関数を実行すれば声が再生されます。
function AudioFunc(){
const m = new Audio('例 http://127.0.0.1:8000/test/songs/audio/2');
m.play();
}Django側
サーバー側(Django側)では、以下のように音声ファイルをデータベースから取り出しreturnすればいい。
データベースから読み出す場合
from django.http import FileResponse
song = models.Song.objects.get(song_id=id)
return FileResponse(song.audio_file.open())
HTTP レスポンスオブジェクトを使う場合(file_obj = ContentFile(response.read(), name='my_song.mp3')を実行しないとき
from django.http import HttpResponse
return HttpResponse(response.read(), content_type='audio/mp3')フロント側でjsonでDjangoのRestFrameworksに以下のようにリクエストするとデータベースに保存した"audio_file": "https://zundahage.onrender.com/my_song_GH087BQ.mp3",などのjsonが返ってくるのでうまくいきません。
function AudioFunc(){
const m = new Audio('http://127.0.0.1:8000/test/songs/audio/2/?format=json');
m.play();
}
またconst m = new Audio('http://127.0.0.1:8000/test/songs/audio/2');にした場合も、Django側で上のreturn処理にいくようにしないとDjango REST frameworkのApi画面が表示されてしまいます。
その辺は、こちらを参考にしてください。
目次へ混合コンテンツ
音声ファイルをXfreeに保存して、そこから読み出して音声を鳴らすようにしてみると
(追記)http://ichige2.html.xdomain.jp/は廃止になったのでつながりません。audio.src = 'http://ichige2.html.xdomain.jp/zundahage/my_song_D9QtZRK.mp3';
audio.play();以下のように混合コンテンツでエラーになります。
Mixed Content: The page at 'https://zundahage.onrender.com/article' was loaded over HTTPS, but requested an insecure element 'http://ichige2.html.xdomain.jp/zundahage/my_song_D9QtZRK.mp3'. This request was automatically upgraded to HTTPS, 混合コンテンツについては↓↓

Firebase Storageに保存したものを読み込めばHTTPSなのでエラーにならないのでそうしました。
Firebase Storageについては↓↓
「ずんだもんに励ましてもらおう!」の使い方
Railway版は毎月21日以降は使えません。Render版は立ち上がるまで数分かかります。
- 初期化-テキスト登録を押してください。(Render版のみ)
- 初期化-音声登録ボタンを押してください。(Render版のみ)
- 初期化するので50秒お待ちください。(Render版のみ)あらかじめ用意したテキストをWEB版VOICEVOX API(低速)でずんだもんの声に変換して保存してます。
(処理完了は確認していません。タイマーでセットしています。定期的に声がします。) - 本文: (article_body) に読んでもらいたい名前を入力して名前登録ボタンを押してください。
- ずんだもん励まして!ボタンを押すと名前を呼んだあと励ましの言葉をかけてもらえます。5回。
- そのほか、本文: (article_body) に入力して「オーム返し(22文字以内)」を押すと読み上げます。
ページをリロードするとデータベースに保存した読み上げテキストと実際に保存されている音声のテキストが表示されます。実際に登録されている音声の1が名前で、6~10が励ましの言葉です。
処理がうまくいかず2重に入る場合があります。
目次へ
天気予報も追加
テキスト入力→ChatGpt API→ずんだもん音声としたいところですが、ChatGpt APIはお金がかかるので気象庁の天気予報JSONファイルをWebAPI的に利用したサンプルアプリを参考に「ずんだもんに天気を聞いてみよう!」機能を追加しました。
天気の聞き方は漢字の県名(栃木より西)を含んだ質問文であれば答えられるようにしてみました。AIではなくプログラムで処理しています。
参考サイトではヘッドラインというjson項目があったようですが、今、やったらそこは空欄になっていました。なので天気予報の詳細からヘッドライン的なところを22文字抽出して声にしています。
ローカルではうまくいくのですがRender上だと前の返答が返ってくることがあります。
Claudeで作り直してCursorでさらに修正しました!(2025/6/24追記)
ClaudeもCursorも課金してません。
新ずんだもんに励ましてもらおう!+ずんだもんに天気を聞いてみよう!(お名前.comVPSにデプロイ)
1、Claudeで以下の要件定義で作ってもらった。
現状画面のスクショと現状処理の参考としてtenki.pyというファイルをtenki.txtに名前を変えて添付しました。
ここhttps://django6.kikuichige.com/zundahage(2026/4/28メモリ節約のため停止)のアプリを全面改修したい。
スクショも添付します。
・Djangoを使用する。
・画面のデザインは変えていい。
・音声は以下の処理で作成
・登録しておく音声はmp3で事前に作っておく。
・使い方音声はID2再生。
・名前を登録したあと、ずんだもん、励ましてボタンを押すとID1番ID6番の順で再生。次にID1番ID7番で再生。同様に~10まで同じことをする。
・「オーム返し」は入力欄に入れた文字を音声にして出力
・「天気予報(漢字の県名(栃木より西)を含んだ質問をしてください)」はtenki.txtを参照して。
・「名前登録」はID1の音声を「入力欄」の文字で音声を更新する。
・「初期化-テキスト登録」「初期化-音声登録」は音声登録の方法があれば、それに変えていい。
ID 登録しておく音声
1 モアちゃん
2 こんばんは。ずんだもんです。名前を登録したあと、ずんだもん、励ましてボタンをおしてください
3 ずんだもんです。文章が長いみたいです。22文字以内で入力してください。
4 4
5 5
6 あなたの頑張りに感動しました
7 あなたは自分の夢を叶えるために、頑張っているよ
8 あなたはたくさんの人にとって、大切な存在だよ
9 あなたは自分自身を信じて、前向きに頑張っているよ
10 あなたはとても素晴らしい人だよ
音声作成処理
errmes='データがありません'
print(errmes)
url=r'https://api.tts.quest/v1/voicevox/?text='+urllib.parse.quote(errmes)+r'&speaker=1'
res = requests.get(url)結果:必要なファイルを作ってくれた。また、アプリ セットアップガイドというローカルでセットアップする手順書を書いてくれた。
しかし、セットアップガイドは参考になるが、Djangoや開発者ツールの知識は必要な内容だった。
ソースコードのほうは、そのままでは全く動かない。ただ、UI(index.html)は、ほぼ使えた。
ということでCursorで修正することにした。
2、Cursor
Djangoが実行可能な状態が前提になっていた。
セットアップ手順
1. プロジェクト作成
bash# Djangoプロジェクト作成
django-admin startproject zundamon_project
cd zundamon_project
# アプリケーション作成
python manage.py startapp zundamonClaudeが作ったsettings.pyやurls.pyなどのファイルをコピペ。
あとはCursorと相談しながら修正。
全面的にオリジナルのものと違っていて、細かくコードは追わないで、修正はCursor任せで提案してくるものをacceptするだけにした。下手に手を出すと余計に大変になりそうだ。
また、フォルダ全体を見てくれているのかわからないので@を押してフォルダ全体と都度、該当するファイルを選択しておいた。意味があるかは分からないが。
Cursorを今回使っていて思ったこと。
最初作ったものは、苦労して全部コードの内容理解した。
今回、ほぼ理解せずAIに任せた。とはいっても自分で最初に作った処理の理解があってこそ、任せられる。
細かいコード内容把握より、現状の問題点やAIが把握できていない出力結果や意図などを的確にAIに伝えることが重要だと思った。
あと、acceptばっかりしてコードの内容把握してないので、ドツボにハマったとき、うまくいったところまで戻す方法を調査したほうがいいなと思った。
立ち止まらずAIと一緒に突き進むと、泥沼にはまりそうな気はする。
無料プランの現状の制限もよくわからない。どのモデルがどのくらい使えて、また使えるようになるのかとか。
こんなの出た。疑わしいアクティビティとか言ってるが制限の関係でバグってるのかなと思った。
しばらく使えなかったが今使えてる。
Your request has been blocked as our system has detected suspicious activity from your account. If you believe this is a mistake, please contact us at hi@cursor.com.
無料でもいい機能が使えるが、いつ制限にひっかるのかが気になるので、あまり気軽に質問しないようにしてる。
あとがき
SQLite3の場合はmanage.pyがあるところにmp3が保存されている。
Django側にリンク先をデータベースに保存し、mp3は別のサーバーに置こうと考えましたが
例えばxfree(混合コンテンツで無理)やブログで使っている■ドメイン取るならお名前.com■のサーバーに保存してリンクをデータベースに保存。しかし動的には無理だしcorsにも引っかかる。サーバー側のcors設定できない。ということでこの形になっています。
posgresなどを使う場合settings.pyのmediaで保存先を設定するみたいです。(実施確認してない)
それと今回1番苦労した点は、同期に関することです。フロントからDjangoへの処理がコードの見た目と違って追い越して実行されたり、DjangoからAPI取得する前に先に進んだり。フロント側の処理は、こちらのYoutubeを参考にさせていただき順番に実行できるようになりました。【ワンピースで覚えるJavaScript】第15回 非同期処理 Promise/async/await(プログラミング入門講座)
しかし、まだ安定した動作はしていません。
目次へ
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
コメント