
Obsidianを使ってみようと思った理由は、あちこちに散らばったデータ(主に個人的ノウハウ)を探すのが大変だったからです。 Obsidianなら、必要な情報にすばやくアクセスできるのではないかと考えました。
この記事では、初めてObsidianを使う方向けの基本操作と、同期機能を使わずに既存データをマークダウンへ変換して取り込む方法を紹介します。 具体的には、WordPress、Zenn(記事を書いてる人向け)とGoogle KeepのデータをPythonでマークダウン形式に変換し、Obsidianへ保存する手順をまとめました。PythonコードはAIに書かせているので他のデータでも手法は流用できると思います。使ったプロンプトも紹介します。
まだ使い始めたばかりですが、現時点で感じているObsidianのメリットは、検索機能が非常に優れていることです。その点についても後半で触れます。
PythonコードはClaudeの無料チャットで作成しました。 AIに「このファイルをマークダウンに変換して」と直接依頼すると、ファイル内容をLLMに読み込ませてしまい、要約されたり、トークン消費が増えたり、大きなファイルだと抜け落ちたりと、さまざまな不具合が起きる可能性があるのでコードだけを作るように依頼しました。
ファイル形式の変換は、1対1で決まったルールに基づくコードを使うほうが確実です。 ファイルの生成経緯を説明すれば、AIは中身を読むのではなく、形式情報をもとに最適な変換コードを書いてくれます。 そのため、AIにコードを書いてもらい、自分のPCで実行する方式にしました。 ちなみに私は無料のAIしか使っていません。AI連携(GeminiCLI、Antigtavity)については後半でふれます。
ただ、今回読み込んだ大量のデータ(Wordpressだけで200記事以上ある)をAIで扱うのは無理だと考えています。
というのは、ため込んだ巨大なデータをどういにかしてもらう処理は、AI(LLM)のしくみ的に向いていないと思います。理由は以下を参考にしてください。


読み込んだデータをAIで処理するには、こちら↓のような工夫が必要だと思います。

マークダウン変換コードは、Pythonが実行できる環境が前提です。Python環境については以下を参考にしてください。

実際に、WordPressの記事を読み込んだ例です。
https://kikuichige.com/35418/の記事をObsidianに読み込んでpdfでエクスポート(Obsidianの機能)した最初の3ページです。
https://django6.kikuichige.com/gaiyou/obsidian_sample.pdf
(見出しのcssは色付けしてます。後述)
結構、しっかり読み込めてます。
Obsidianとは?
Obsidianは、Markdown形式でメモや文章を書けるアプリです。
特徴は、すべてのデータをローカルに保存できること。
つまり、Google DocsやNotionのようにクラウド依存ではなく、自分のPCの中にデータを保存します。
主なメリット
- 無料
- 動作が軽い
- オフラインでも使える
- 自分でファイル管理できる
- マークダウンファイルの編集がやりやすい。
- スクショなどの画像も簡単に貼り付け可能
- 検索機能が充実。ファイルをまたいだ全文検索もできます。
(例:line:(AI 無料)で検索すると同じ行内に「AI」と「無料」が含まれるファイルを探し出し、その箇所を一覧表示してくれる(後述)など) - 全文検索結果が左表示されるので、右側ですぐに編集可能
基本的な使い方はこちらのYoutubeがおすすめです。
見出しを色分けするcssはぜひやったほうがいいです。こちらのYoutubeのものを使わせていただきました。
(cssファイルを配置するのですが、必ず拡張子が.cssになるようにしないとうまくいきません。メモ帳を使う場合「ファイルの種類」を「すべて」にしてファイル名.cssにしてください。種類が「.txt」のままだとファイル名.css.txtファイルになってしまいます。)
Obsidianをインストールする
私のパソコンはWindows11です。こちら↓↓です。

公式サイトへアクセス
まずはObsidianの公式サイトへアクセスします。
Windowsの場合
「Get Obsidian for Windows」→「Download for Windows」をクリックして、自分のOS版をダウンロードしてください。
Windowsでインストールする
ダウンロードした `.exe` ファイルを開きます。例”Obsidian-1.12.7.exe”
基本的には「次へ」を押していくだけでOKです。
インストールが終わると、Obsidianが起動します。
Vault(保管庫)を作る
Obsidianでは、ノート(メモ)を保存するフォルダのことを「Vault(ヴォルト)」と呼びます。
最初に起動すると、Vault作成画面が表示されます。
新しいVaultを作成
「Create new vault」(保管庫を新規作成する)をクリックします。
例えば以下のように設定します。
| Vault名 | 20260519Vault |
| 保存場所 | ドキュメント配下など |
「Create」を押すと、Vaultが作成されます。
また、左下の保管庫名をクリック→「保管庫を管理で」をクリックで切り替えや新規作成ができます。
Obsidianの画面構成
主に使うのは以下です。
| 場所 | 内容 |
| 左サイドバー(リボン) | クイックスイッチャーなどのボタン |
| 左サイドバー表示域 | ファイル一覧、検索結果、お気に入りを選択して切り替える。 |
| 中央 | ノートを書くエリア |
最初のノートを書いてみる
新規ノートを作成
左上の「新規ノート」アイコンをクリックします。
ファイル名は本文の先頭行とリンクしており、拡張子は自動的に .md になります。 マークダウン記法を使わなくても普通のテキストとして保存できますが、AIと連携する場合はマークダウン記法を使ったほうが便利なようです。
Markdownで書いてみる
以下を入力してみましょう。
初めてのObsidianノート
こんにちは。
これはObsidianで書いた記事です。
## 見出し2
- リスト1
- リスト2
**太字**も使えます。自動的に##、-、**などのマークダウン記法で書いたところはフォーカスが外れるとマークダウン形式に変換表示されます。カーソルをマークダウン記法の文字に持っていくとマークダウン記法表示に変わります。
また自動的に先頭行がファイル名になって「初めてのObsidianノート.md」という名前で保存されています。
Windowsエクスプローラーで「Create new vault」で作ったvaultの場所を見てみるとファイルが確認できます。
補足:マークダウンファイル(*.md)とテキストファイル(*.txt)の違いは、アプリが拡張子によって表示形式を変えるだけです。
例:# の場合
マークダウンとして扱われると、「# + 半角スペース」から改行までを見出しと判断し、指定された文字サイズや色で表示します。
テキストとして扱われると、# をそのまま文字として表示します。
Obsidianでは基本的にマークダウン表示されますが、テキスト表示に切り替える(手動/自動)ことも可能です。
Markdownの基本だけ覚えよう
よく使う記法だけ覚えれば十分です。
| やりたいこと | Markdown |
| 見出し | # 見出し |
| 小見出し | ## 小見出し |
| 箇条書き | – 項目 |
| 番号付き | 1. 項目 |
| 太字 | **文字** |
| コード | “ `code` “ |
これだけでも、かなり快適に記事を書けます。
既存のWordPress記事をObsidianへ取り込む方法
ここでは、既存のWordPress記事をObsidianへ移行する方法を紹介します。WordPressを使って記事を書いてる人が対象です。
具体的手順はWordPress標準のWordPress ExportでエクスポートしてPythonでマークダウン形式に変換します。
WordPress Export
WordPressにはエクスポート機能があります。
手順
1. WordPress管理画面を開く
2. 「ツール」→「エクスポート」
3. 「すべてのコンテンツ」を選択
4. XMLファイルをダウンロード
ダウンロードしたxmlファイルを以下のコードを実行してマークダウン形式に変換します。
コードは以下のプロンプトでClaudeの無料チャットで作りました。
プロンプト:「WordPress管理画面の 「ツール」→「エクスポート」で出力したxmlファイルをpythonを使ってobsidianで扱えるマークダウン形式に変換するコードを書いて」
修正依頼や自分で修正することもなく1発目の回答そのまま使ってます。
コードはhttps://github.com/miyamiko/obsidian_markdownのpython wp_to_obsidian.py
使い方:
pip install markdownify
(markdownify があると Markdown の変換品質が大幅に向上するようです。なくても動作します。)
python wp_to_obsidian.pyとダウンロードしたxmlファイル(wordpress-export.xml)を同じディレクトリにおいて
python wp_to_obsidian.py <wordpress-export.xml> [出力先ディレクトリ]
例:python wp_to_obsidian.py WordPress.2026-05-19all2.xml
[出力先ディレクトリ]は省略するとobsidian_exportというディレクトリを作って、そこに出力します。エラーの場合
今回、WordPressの記事で以下のような特殊文字を使ったのでエラーが出ました。
コードをClaudeに頼んで修正してもいいですが、個人的な経験でAIに特殊文字がらみの修正を依頼すると意図が伝わらず(AIが把握できない)、うまくいかないことが多いのでxmlファイルを修正しました。
このようなエラーが出た場合。
xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 61908, column 424
エラー発生が発生してるxmlの行と文字位置を確認して、xmlを修正して再度やってみてください。
エラー周辺line 61908, column 423~を確認
【Ajax】のが変換できない文字だったので消した。
xmlファイルをなおした。
【Ajax】ローカルファイルを読み込もうとしたらCORSエラーが発生したので解決した
→【Ajax】ローカルファイルを読み込もうとしたらCORSエラーが発生したので解決したObsidianのVallt(保管庫)へ移動
postsディレクトリを使います。attachmentなどのディレクトリもできますが、中身を見て役に立たなそうだったら削除してください。(私は使ってません。)
WindowsエクスプローラーでVault(保管庫)へ展開されたpostsディレクトリを移動
Google KeepをObsidianへ取り込む方法
今度は、Google Keepのデータをマークダウン形式に変換する方法です。こちらもダウンロードしたものをPythonで変換します。
Google Takeoutを使う
大量のKeepメモを移行したい場合におすすめです。
Google Takeoutとは?
Googleデータをまとめてエクスポートできる機能です。
—
手順
1. Google Takeoutを開く
2. 「選択をすべて解除」をクリック
3. 「Google Keep」のみチェック
エクスポート先:ダウンロード リンクをメールで送信
頻度:1 回のエクスポート
ファイル形式::zip
ファイルサイズ:2GB
4. エクスポート作成
5. メールできたリンクからzipファイルをダウンロード
6.すべて展開
解凍すると、HTML形式やJSON形式でKeepメモが保存されています。
html→マークダウン(非推奨)
こちらのを使うより下のJSON→マークダウンのほうがおすすめです!
コードは以下のプロンプトでClaudeの無料チャットで作りました。
プロンプト:
1回目「htmlをマークダウンに変換するpythonコード」
2回目「あるフォルダに入っているhtmlを全部変換して別のフォルダに保存したい」
コードはhttps://github.com/miyamiko/obsidian_markdownのhtml_to_markdown.py と batch_convert.py
セットアップ
html_to_markdown.py と batch_convert.py を同じフォルダに置きます。
# 基本(htmlフォルダ → markdownフォルダ)
python batch_convert.py ./html_files ./markdown_files
# サブフォルダも含めて再帰的に変換
python batch_convert.py ./html_files ./markdown_files --recursive
# 文字コードを指定(Shift-JISのHTMLなど)
python batch_convert.py ./html_files ./markdown_files --encoding shift_jis
# .htmも対象にする
python batch_convert.py ./html_files ./markdown_files --ext .html .htmWindowsエクスプローラーでVault(保管庫)へ展開されたmarkdown_filesディレクトリを移動
JSON→マークダウン
コードは以下のプロンプトでClaudeの無料チャットで作りました。
プロンプト:
1回目「googleキープのデータをGoogle Takeoutでzipでダウンロードして展開しました。htmlは先ほどのpythonコードでマークダウンにできました。今回はjsonファイルを同じようにマークダウンにしてほしい。」
2回目「エラーが出ました。エラーのファイルは飛ばして、飛ばしたことが分かるようにしてください。
[OK] Transformerのポイント.json → Transformerのポイント.md
[OK] VPS.json → vps\VPS.md
[OK] Vrew.json → その他\Vrew.md
Traceback (most recent call last):
OSError: [Errno 22] Invalid argument: ‘obsidian\Keep\VSCode\VSCode Tips\n\n・変換候補非表示\n—\n\n__ ✨ 候補を出さないようにする方法\n\n___ 1. インテリセンス自動表示をオフにする\n1. __設定.md’」
コードはhttps://github.com/miyamiko/obsidian_markdownのkeep_json_to_md.py
**標準ライブラリのみ**で動作します。`pip install` 不要です。
使い方
# 基本
python keep_json_to_md.py ./Takeout/Keep ./obsidian/Keep
# ゴミ箱のメモも含める
python keep_json_to_md.py ./Takeout/Keep ./obsidian/Keep --include-trashed
# アーカイブをスキップ
python keep_json_to_md.py ./Takeout/Keep ./obsidian/Keep --skip-archived出力される構造
obsidian/Keep/
├── 買い物リスト.md # ラベルなしのメモ
├── 仕事/ # ラベル名のフォルダ
│ └── 会議メモ.md
├── アイデア/
│ └── プロジェクト案.md
├── _archived/ # アーカイブ済み
├── _trashed/ # ゴミ箱(--include-trashed 時のみ)
└── _attachments/ # 添付画像・ファイル
KeepメモをObsidianへ入れる
変換されたものをObsidianの保管庫へ移動。
jsonファイルからマークダウンへ変換したファイルの方がkeepに近い情報(添付資料とか)を保持できていると思うのでおすすめ。
Zenn
自分の書いたZennであればエクスポートできます。また、元々マークダウン形式なので、ダウンロードして「すべてを展開」で展開したら、そのままVaultに持っていけば使えます。
詳細は以下↓

検索
Obsidianの検索は非常に強力です。
ノート内検索
開いてるノート内を対象に検索。
ショートカットキー:CTRL+F
ファイル名検索
ファイルを探すときファイル名で検索。
ショートカットキー:CTRL+o。
リボンのクイックスイッチャーでもok。CTRL+ファイル名クリックで別タグで開かれる。
全文検索(おすすめ!)
ノートの本文に含まれる単語・文章を横断的に検索できる方法。
左上の虫眼鏡(🔍アイコン)。
ショートカットキー:CTRL+シフト+F
全文検索オプションが豊富
| 演算子 | 例 | 説明 |
|---|---|---|
file: | file:2026 | ファイル名に「2026」が含まれるノートに絞り込む |
path: | path:20_Notes | 特定のフォルダ(例:20_Notes)内のノートのみ表示 |
tag: | tag:#type/note | 特定のタグを持つノートを表示 |
content: | content:(AI 仕組み) | 本文中に「AI」という単語を含むノートを表示 |
line: | line:(TODO DONE) | 同一行内に指定したキーワードがあるノートを表示(例:1行にTODO DONEが書いてあるノート) |
- (マイナス) | -tag:#archive-:topics | 特定の条件を除外する(例:アーカイブタグを除外) (例:topicsという文字を除外) |
(おすすめ!)全文検索オプションline:をお気に入り登録して使うのが1番!
Obsidianで情報を探すのは、このやり方が1番おすすめです。
単語1個ではなく、1行に指定したキーワードA、Bが存在するものを抽出できるので、かなり絞れます。
使用例
ブックマークに全文検索オプションを登録しておくとワンタッチで「1行にキーワードA、キーワードBが入っている行」を検索できます。
ブックマークをクリックした状態。事前に登録した検索条件が登録されています。
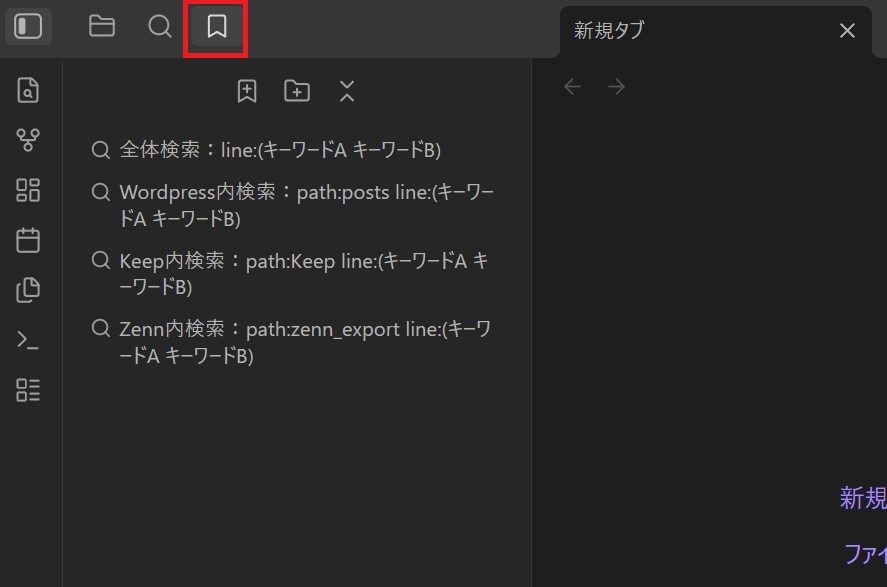
ブックマーク済みの条件(全体検索:line:(キーワードA キーワードB))をクリック
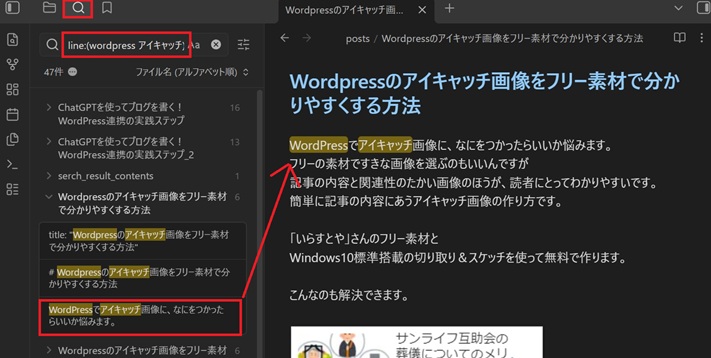
キーワードAをWordpress、キーワードBをアイキャッチに変更→検索結果から見たいものをクリックして表示
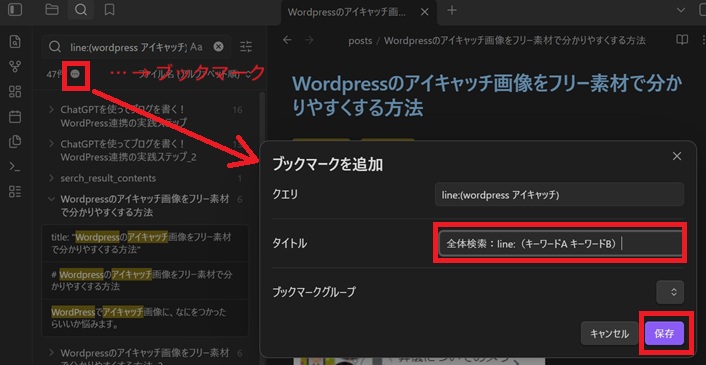
ブックマークにline:を登録するやり方
虫眼鏡(検索)→ line:(キーワードA キーワードB)(キーワードA、Bはなんでもいい)
→ … → ブックマーク → タイトルにブックマークとして表示したい文字を書く、例:全体検索:line:(キーワードA キーワードB)
フォルダを指定したい場合
path:フォルダ line:(キーワードA キーワードB)
例:path:posts line:(WordPress アイキャッチ)
AI連携は後回し
AI は GeminiCli(Antigravity) が無料で、保管庫への読み書きもできるので連携するとしたらGeminiCli(Antigravity)を使ってます。
2026/6/18からGeminiCLIは無料ユーザーはつかえなくなるようなのでGoogle Antigtavityをつかうことにしました。(この記事を書いている時点ではGeminiCLIを使っていたのでGeminiCLIが前提の記事になっています。)

ただ、AI にファイルを直接いじらせて再起不能になるのは避けたいし、思った通りに動かないことも多いので、コードやテキストをコピペして AI チャットに貼り付ける運用のほうが安心だと感じています。(AIにパソコンの中のファイルを操作させる場合、何があってもいいように常にバックアップを意識して使いましょう。AIを信頼すると痛い目を見ます。)
コード生成や文章要約、ドラフト作成、修正のような処理は Python だけではできませんが、ファイル操作や文字置換のような作業は、AI に Python コードを書かせて自分で実行するほうが、処理内容を確認できて、不具合が起きたときの原因特定も AI に丸投げするより効率が良い気がします。

NoteBookLM
AI連携したとしてもNotebookLMのような使い方になると思いますが、ソースが巨大だとあまり使い物にならないような気がしてます。
試しに、NoteBookLMで「新しいノートブック」→ソースに「ウェブサイト」でObsidianの公式ヘルプを追加して、使い方が分からないことを聞いたけど、全然、答えにたどり着けませんでした。
今のところAI連携よりも、まずはObsidianの魅力が何なのかを理解したいと思っています。ノートの書き方やリンクの活用方法など、運用ルールをしっかり整えていくつもりです。Obsidianがどんなツールなのかを把握した上で、AI連携を検討する方が良いと感じています。
スナップレイアウト(Windows11標準機能)を使ってObsidianとGeminiCli(Google AntigtavityCLI)を並べて使う方法
しかし、ちょっとだけ連携して使ってみた。ここの章の内容の材料を記述したファイル(2026-05-25.md)をおきGeminiCli(Google AntigtavityCLI)で書かせてみました。Obsidianでプラグインを使ってGeminiCli(Google AntigtavityCLI)を表示するのではなく、Windows11のスナップレイアウト(複数のウィンドウを画面上に綺麗に整列・分割表示できる標準機能)で横並びで表示させるやり方をまとめてます。(個人的に、プラグインはセキュリティ面や不具合時の原因特定が難しくなるため、VSコードやWordPressでも必要最低限に抑えています。)
プロンプト:
@2026-05-25.md
を元にObsidianでスナップレイアウトを使ってGeminiCliを使う方法をまとめて、
@をつけると対象とするファイル名を指定できます。(Antigravity2.0は、@で指定できないようなので、フルパスを貼り付けて使ってます。具体的には、エクスプローラーで対象ファイルを右クリック→パスのコピー)
結果は「ObsidianでGeminiCliを使う方法.md」というファイルができた。
↓↓↓この章のここから下は、できたファイルの中身を貼り付けた(多少手動修正した。GEMINI.md に関しては私がよくpython使うのでちょっと特殊です。)↓↓
Obsidianでの執筆や管理をGeminiCli(Google AntigtavityCLI)で効率化するためのセットアップ手順です。
画面レイアウトの設定(スナップレイアウト)
Windows 11のスナップレイアウト機能を使用して、Obsidianとターミナル(PowerShell)を最適な比率で並べます。
- アプリの起動: ObsidianとPowerShellをそれぞれ立ち上げておきます。
- レイアウトの起動: Obsidianを選択した状態で
Windowsキー + Zを押します。 - 配置の選択: 表示されるレイアウト候補から「4番(左側が広いタイプ)」の左側をクリックします。
- これにより、画面の左側約2/3がObsidianになります。
- 右側の選択: 画面右側に表示されるアプリ候補からPowerShellを選択します。
これにより、左側でメモを確認・編集しながら、右側でGeminiCliへの命令を実行できる環境が整います。
GeminiCli(Google AntigtavityCLI)の準備と設定
各Vault(ディレクトリ)ごとにGeminiCli(Google AntigtavityCLI)の挙動を制御するための設定ファイルを配置します。(設定しなくてもいい)
- 設定ファイルの配置: 対象とするVaultのルートディレクトリ(gemini(agy)コマンドを打つところ)に
GEMINI.md(またはgemini.md)を配置します。- このファイルには、GeminiCli(Google AntigtavityCLI)が守るべき「掟(ガイドライン)」を記述します(例:パッケージ管理には
uvを使う、型ヒントを義務化するなど)。
- このファイルには、GeminiCli(Google AntigtavityCLI)が守るべき「掟(ガイドライン)」を記述します(例:パッケージ管理には
- ディレクトリの移動: PowerShellで、対象のVaultディレクトリへ移動します。
- 例:
cd C:\Users\user\Documents\obsidian\my_vault
- 例:
- GeminiCli(Google AntigtavityCLI)の起動: コマンドラインで
gemini(agy) を実行します。
GEMINI.md の役割
こちら↓でAntigravityとGemini.mdの関係が分かると思います。

GEMINI.md は、GeminiCli(Google AntigtavityCLI)がそのディレクトリで作業する際の内容を規定する「ルールブック」として機能します。
- 開発品質の維持: コードの書き方、型ヒントの有無、1行の長さなどのスタイルを統一させます。
- ツールの指定:
pipではなくuvを使うなど、特定のワークフローを強制できます。
このファイルを置いておくことで、GeminiCli(Google AntigtavityCLI)は常にプロジェクトの文脈やルールを理解した状態でアシストを行えるようになります。
(AI連携の感想)これではObsidianを使ってる意味がない。GeminiCLI(Google AntigtavityCLI)を普通に使ってるだけだった。AIに中身を確認させながら検索するような処理はトークン消費が多くなるし、コンテキストウィンドウも消費するので、いい結果は得られないのではと思ってます。なのでObsidianの検索機能などをフル活用してAIに読み込ませるファイルを手動で絞ったあと、プロンプトで、「このファイルを~して」という感じで作業させてます。
トークン消費やコンテキストウィンドウの話は以下を参考にしてください。

所感
既存データを入れただけでは、全文検索以外のメリットはまだ感じにくいですが、 自分の書いたWordPress、Zenn、Keepを横断検索できるようになったのは非常に有用です。ただし、このような全文検索が目的だったらObsidianではなくてもいいかもしれない。
AIとの連携に関しては、AIのコンテキストサイズが広がったとはいえ、巨大なデータをそのまま扱うと精度が落ちる可能性があるため、工夫が必要だと思います。
結局、ノート(データ)が、しっかりしたルールで作られたものでないと全文検索するぐらいしか活用法がない。AIつかっても巨大なデータだと無題にトークン消費して、ろくな結果は得られないのではないかと思います。
Obsidianとは、どんなツールなのかを理解することが重要だと思いました。
今後
- ObsidianでObsidianの使い方をまとめていたら理解が深まり、ますます楽しくなった。標準機能を詳しく知ることで、これまでとは違う情報管理ができそうな気がする。(実は新たなごちゃごちゃを生み出しているだけかもしれないが😭)
- 自分の書いたWordPress、Zenn、Keepのデータは、Obsidianの検索機能を利用する。修正したい場合は、Obsidianで修正せず、元を修正する。同期に関しては、今回の方法でObsidianに読み込むことで同期をとる(WordPress、Zenn)。
- Keepの使用をやめObsidianを使う。
- 既存データの整理は行わず、全文検索で必要な情報を探す。AIで探したり、既存文章をもとに新たな文章を作るのは、うまくいく気がしないので使わない。
- ノートの書き方やリンクの貼り方、フォルダ分け等、運用方法をAIに相談しながらしっかり作りたいと思います。実際に利用する段階では、あまりAI使わないでも済みそうだと感じてます。
- Obsidianの使い方に関しては、現在模索中なので改めて記事にします。