インストールなしでPythonが実行できるGoogle Colaboratoryを使えば
コピペでPythonのプログラムが簡単に実行できます。
右クリックで貼り付けられないときの対策もご紹介します。
Web上で動くのでMacでも動きます。

注意点
すべてのプログラムが実行できるわけではありません。
デスクトップのみでしか動かすことができないプログラムもあります。
例えばPyAutoGuiなどWindowsの操作を自動化するライブラリや
コピペ用のライブラリpyperclipなどは使えません。
正確には使えるかもしれませんが大変です。
そういうのはGoogle Colaboratoryでやろうとせず
Anaconda(python実行環境)などをパソコンにインストールして使ったほうが楽です。


Pythonとは
初心者に優しいプログラミング言語ですが
できることはたくさんあります。
自分のパソコンに開発環境をインストールして使うこともできます。
今回はgoogleがウェブ上に用意しているGoogle Colaboratory を使用します。

Python使用上の注意点
pipというコマンドがあります。
プログラムで使えるようにライブラリをインストールする命令ですが
悪意のあるライブラリもインストールできてしまうので
pipを使う前にはそのライブラリについて調べてからつかいましょう。
便利そうな機能なのにググっても極端に情報が少ない場合はやめましょう。
またこの記事と矛盾しますが
内容を理解しないでコードをコピペして実行するのは危険です。
悪意のある人が作っているかもしれません。(悪意はなくても、あまり吟味せず載せているかもしれません。)
ChatGPT関連の記事見て最近、始めた方は慎重になった方がいいと思います。ちなみに私は今のところ(2025/2/3)有料のAPI使ったことないです。今後も使わないかも。自分で課金してまで使う必要があるものなのか判断できるまで待った方がいいとおもいます。


Google Colaboratory とは
ブラウザから Python を記述、実行できるサービスです。
無料です。
Web上ですべて完結するのでインストールも不要で
パソコンへはインストールしません。
Googleアカウントがあれば使えます。
Google Colaboratory を立ち上げと貼り付け方(右クリック使わない方法)
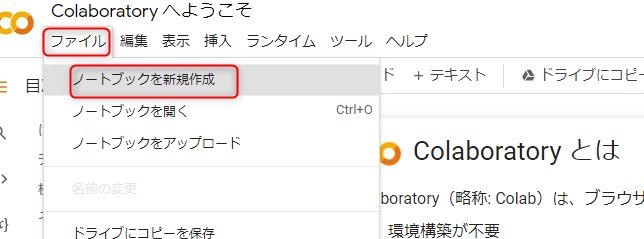
Google Colaboratory をクリックします。
ファイル→ノートブックを新規作成
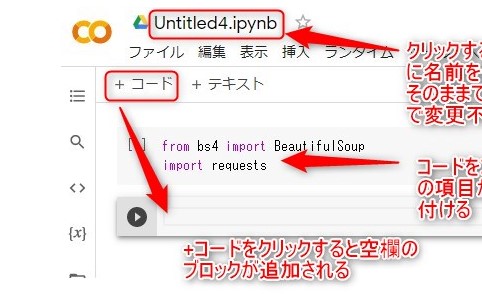
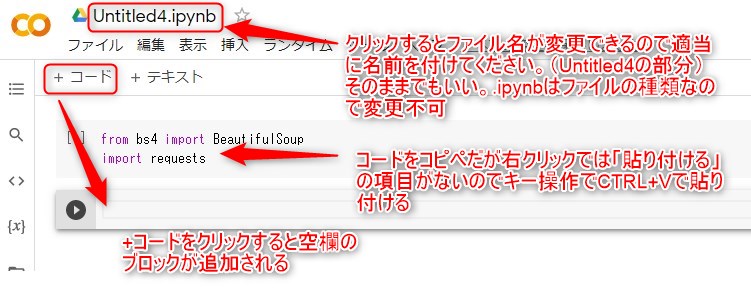
ファイル名*.ipynbで*の部分は任意に変更してください。そのままでもいい。
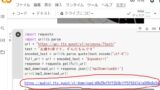
プログラムを1ブロックずつ貼り付けてください。
右クリックは使えませんのでキー操作でCTRL+Vで貼り付けてください。
ちなみに「全て選択」はCTRL+A、「コピー」はCTRL+C
+コードで空のブロックが追加されます。
プログラム実行は左の▶を押せば実行されます。
Google Colaboratoryを使った学習は
いまにゅのプログラミング塾さんのYoutube
中学生でもわかるPython入門シリーズがおすすめです。

イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
コメント