Djangoで処理に時間がかかると何かしらのエラーが発生する。
原因はリクエストに対するレスポンスに時間がかかっているからです。
エラーになる時間はサーバーによって決まってます。
処理に時間のかかるアプリの例だとスクレーピングアプリがあります。
スクレーピングの場合、アクセスを繰り返しても
サーバーに負荷をかけないようにする必要があります。
単純に1秒(time.sleep(1))休んでリクエストを出すように作ってしまうとタイムアウトになります。
そういうソフトをDjangoで動かす方法です。
非同期処理で実現するのが正攻法ですが
今回紹介するのは力技です。
なので非同期処理を実装しようとして挫折した場合の最終手段として考えてください。
何もインストールしないでも無料のWEBサービスPaizaCloudで
サンプルプログラムお名前.comVPS(有料)デプロイが作れます。
サンプルプログラムRenderデプロイ(表示するまで数分かかることがあります。毎月20日~月末は停止します。)(これはRender上で動かしてる)が作れます。
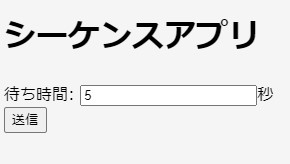
このプログラムは待ち時間に秒数(整数のみ)を入れて送信を押すと
シーケンスNoの数字が5まで1づつ増え完了します。
30以上にしてレスポンスを返さないようにするとエラーが発生します。
これはHerokuのタイムアウト時間以上にしたからです。(PaizaCloudは60秒)
つまりこのプログラムを応用して
30秒以上かかる処理を分割してシーケンスNo上限を5ではなく
延ばせばエラーにならずに長い処理を実行できます。
(2025/9/19追記)gunicornのtimeoutが短いことが原因の場合
経験した内容を書いておきます。
現象
以下のアプリでDjangoのviews.pyからresponse = requests.get(url)をしていた。
接続先はGeminiのAPIです。ここからのレスポンスが遅いため不具合が発生してました。
対策
Djangoのアプリは以下で起動していました。
gunicorn --config gunicorn.conf.py flashcard_backend.wsgi:application
ここで読み込んでいるgunicorn.conf.pyにtimeout = 30がありました。
copilotに聞いたら「Gunicornが30秒以上かかるリクエストを強制的に切断しているということ」でした。
なので、timeoutを180にしたら改善しました。現在使っているサーバーは以下です。DockerでNginxとDjangoを別コンテナで起動しproxy接続しています。

2024/4お名前.comのレンタルサーバーからVPSへ移行したときの記録になります。
私の環境の場合、今回の件に関係する要因をcopilotに聞いた答えを貼っておきます。
Gunicornの
timeout設定が短いと、Djangoアプリが処理中でも Gunicornが接続を強制的に切断してしまいます。これにより、Nginxは「upstream prematurely closed connection」というエラーを出し、502 Bad Gatewayになります。
補足:「upstream」はGunicornを含む“アプリケーションサーバー側”の総称であり、Nginxから見た“リクエストの送り先”です。一方で、Nginx側にも
proxy_read_timeoutやproxy_connect_timeoutなどのタイムアウト設定があります。これらは「Nginxがどれだけ待てるか」を決めるもので、Gunicornのtimeoutよりも長く設定しておく必要があります。例えば、Gunicornの
timeout = 30のままでは、Nginxがproxy_read_timeout = 36000sと長く待つ設定でも意味がありません。先にGunicornが接続を切ってしまうからです。実際に私の環境では、
gunicorn.conf.pyにtimeout = 30が設定されていたため、Gemini APIからのレスポンスが遅いときに接続が切れてしまい、Nginxが502エラーを返していました。timeout = 180に変更したところ、問題は解消されました。
NginxとGunicornの役割:
🧩 NginxとGunicornの基本的な違い
| 項目 | Nginx | Gunicorn |
|---|---|---|
| 役割 | Webサーバー/リバースプロキシ | Pythonアプリケーションサーバー |
| 主な仕事 | クライアント(ブラウザ)との通信を担当 | DjangoなどのPythonアプリを実行・処理する |
| リクエストの流れ | クライアント → Nginx → Gunicorn → Django → Nginx → クライアント | Gunicorn → Django(Nginxがなければ直接) |
| 静的ファイル | HTML/CSS/JSなどを高速に配信できる | 静的ファイルの配信は苦手(基本的に非対応) |
| 同時接続 | 高速・大量の同時接続に強い(非同期処理) | 同時接続数はワーカー数に依存(同期処理が基本) |
| タイムアウト | リクエストの待ち時間を制御(proxy_read_timeoutなど) 私の場合: /etc/nginx/includes/proxy_backend.conf:proxy_connect_timeout 60s; /etc/nginx/includes/proxy_backend.conf:proxy_read_timeout 36000s; | 処理時間の上限を制御(timeout) |
🛠 どうして両方使うの?
- Nginxは玄関口:インターネットからのアクセスを受け取り、静的ファイルを配信したり、DjangoへのリクエストをGunicornに渡したりします。
- Gunicornは裏方:Djangoアプリのロジックを実行し、リクエストに応じたレスポンスを生成します。
つまり、Nginxが受付係で、Gunicornが調理係みたいなイメージです。
🔥 タイムアウトの関係性
- Nginxが「まだレスポンス来ないな…」と待っている間に、
- Gunicornが「もう30秒経ったから切るよ」と接続を終了すると、
- Nginxは「えっ、途中で切られた!」と判断して502エラーを返します。
このように、Gunicornのタイムアウトが短すぎると、Nginxが待っていても意味がないということになります。
質問:proxy_connect_timeout 60s;でgunicornのtimeoutを180にしているが、60以上は意味がないか?
proxy_connect_timeout が 60秒でも gunicorn の timeout = 180 は意味があります。
なぜなら、両者はまったく異なるタイミングの「待ち時間」を制御しているからです。
🔍 タイムアウトの役割の違い
| 設定項目 | 役割・タイミング |
|---|---|
proxy_connect_timeout | NginxがGunicornに接続を開始するまでの待ち時間(接続確立まで) |
gunicorn timeout | Gunicornがリクエスト処理にかけてよい最大時間(処理中のタイムアウト) |
✅ 具体的な流れで見ると…
- クライアントがNginxにリクエストを送る
- NginxがGunicornに接続しようとする(このときの待ち時間が
proxy_connect_timeout) - GunicornがDjangoでリクエストを処理する(この処理時間の上限が
gunicorn timeout) - 処理が終わればレスポンスがNginxに返り、クライアントに届けられる
💡 つまりどうなる?
proxy_connect_timeout = 60sは「Gunicornが落ちてる」「ネットワークが不安定」などで接続できないときの猶予時間。gunicorn timeout = 180sは「処理が重い」「外部APIが遅い」などで処理に時間がかかるときの猶予時間。
なので、60秒以上の gunicorn timeout は十分意味があります。
むしろ、proxy_connect_timeout は通常数秒〜数十秒で十分です。
エラーになる原因(スクレーピングアプリをDjango化した私の場合)
ここに至るまでの経緯です。
JupiterNotebookやGoogle ColaboratoryでうまくいったPythonプログラムも
Djangoの中に組み込むとエラーが発生しました。
実際のエラー(PaizaCloudで実行)
Page not found (404)
Request Method: POST
Request URL: http://localhost-*****-1.paiza-user-free.cloud:8000/index.html
Using the URLconf defined in s_word.urls, Django tried these URL patterns, in this order:
admin/
[name='index']
The current path, index.html, didn't match any of these.処理の途中でindex.htmlに戻ろうとする。
今回index.htmlへ飛ぼうとしても、urls.pyにはとび先記載していないので
Page not foundのエラーが出ます。
しかしなぜこうなるのかというと
サーバー(PaizaCloud)で処理時間がかかりすぎると判断され
このような挙動をしています。
何度も実行されるtime.sleep(1)をなくすとうまくいきます。
対策として非同期処理(ある処理が待ちの状態の時、他の処理を先に進める)はどうか?
Djangoで非同期処理を実装する方法(Celery、Redis)Macローカル編で
重い処理に対する解決策が紹介されています。
こちら実際の導入サンプル付き
【Python x Django】Djangoによる非同期処理実装(Cerery,Redis)
しかし色々インストール必要そうでPaizaCloudやその先のHerokuで苦労しそうなのでやってません。
またはtime.sleep(1)の間にほかの処理を進めるようなことは
スクレーピングの場合できないと思い同期処理のまま対策することにしました。
リクエストに対してレスポンスの時間が遅すぎるのが原因なので
リクエストに対し頻繁にレスポンスするようにプログラムを修正しました。
対策の結論として
- 処理をシーケンスNoで管理して分割する。
- レスポンスをタイムアウト以内に返す。
- すかさずJavaScriptでリクエストgetを発生させる。
- データをセッションに保存する。
JavaScriptでrequestを発生させる
対策1、2は処理時間のかかるループを分割して
レスポンスをタイムアウト以内に返します。
その際1個の処理終了時シーケンスNoを増やしセッションに保存(後述)
対策3で、すかさず自動でリクエストを発生させ
保存しておいたセッションNoにしたがって処理を進める。
自動でリクエストを発生させる部分について解説します。
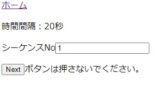
レスポンスで表示させる画面に以下のようにボタンを配置し
JavaScriptで画面表示と同時にrequestを発生させます。
後はViewでrequest、getの処理にシーケンスNoを読みだして
続きの処理を実行すればいいわけです。
<form method="get" action="">
{% csrf_token %}
<p><input type="submit" id="button" value="Next"><label>ボタンは押さないでください。</label></p>
</form>
<script>
document.getElementById('button').click();
</script>
データを保持しておく方法
シーケンスNoを保存する方法はセッションを使います。
セッションについては以下を参考にしてください。
下の2つのを見ればセッションの使い方はわかります。
一次的に保存しておく変数ならデータベースを使うより
セッションを使ったほうが簡単で扱いやすいです。
セッションの仕組みを理解しよう
【Django】セッション(session)を使用してviewsでデータを扱う
上記の補足の説明をしておくと
INSTALLED_APPSとMIDDLEWAREにはすでに必要なものが入っていた。
settings.pyに追加したのはどこに保存するかを指定する以下のコードだけ
SESSION_ENGINE = "django.contrib.sessions.backends.cache" #キャッシで保存
あとは
request.session['任意の名前']にデータを出し入れすれば済む。
migrateも必要なし。viewsで使うには特にimportしなくてもエラーにならなかったが
viewsから別のファイルで定義してる関数を呼び出しているところでは
その関数でセッション(request)を使おうとするとエラーになる。
HttpRequestクラスのインスタンス変数requestらしいです。
なのでviewsのみでセッションを使用するように処理を変更した。
Viewクラスを継承したクラスの場合requestに関するライブラリを
改めてimportしなくても使えるようになっているようです。
目次へ
セッション使用時注意点
少しはまったので書いておきます。
定義していないキーのセッションを参照しようとすると
KeyErrorになるので
request.session['key']=''や
if not 'key' in request.session:
request.session['key']=''
という感じで使う前に何かしら入れておく
今回の方法で作ったプログラムでキャッシュに保存だと
PaizaCloudでうまくいったがHerokuだとKeyErrorになった。
多分何らかの原因でキャッシュIDが変わってしまっている?
SESSION_ENGINE = "django.contrib.sessions.backends.cache" #キャッシュで保存
↓↓↓
SESSION_ENGINE = "django.contrib.sessions.backends.signed_cookies" #クッキーで保存
に変更することでうまくいった。登録したIDは、「PHPSESSID」という名前のクッキーとして登録されます。
自動的にクッキーに登録された「PHPSESSID」がセッションIDを保持しています。
セッションIDをクッキーで保存しているため、
Webブラウザでクッキー設定を無効にされるとセッションも利用できなくなるので
注意が必要になります。
Ajax
Ajax処理も検討しましたが
AjaxはJavaScriptでパソコン側の非同期処理なので
今回は使えませんでした。
async/awaitなどJavaScriptの非同期処理も同じく使えないと思います。
今回はレスポンスを出すほうに対策が必要です。
JavaScriptの非同期処理はレスポンスを待つ方の対策です。
しかし参考になるかもしれないので書いときます。
Ajaxについてはこちらを参考にしてください。
【django】Ajaxによる非同期通信:動的にページ更新する方法
DjangoでAjax処理を行う方法(GET/POST)で公開していただいているGitHubのコードを
PaizaCloudにクローンして実行してみました。
GitHubの下の方にQuick startが書いてありますが
2022/3/3時点のPaizaCloudで動かすために、いくつか補足させていただきます。
クローン後
cd ajax
pip install django-bootstrap4
settings.py変更
ALLOWED_HOSTS = []→['*']
LANGUAGE_CODE = 'ja-JP'→'ja'
python manage.py migrate
python manage.py createsuperuser後
ユーザ名 空欄(=ubuntu)
メールはリターン
パスワード2回password
y
base.html変更
{% load staticfiles %}しっかり削除する→{% load static %}
これで実行できます。
実行したら「東京」を押せば記事に出ている画面が表示されます。効果を確認するために以下のようにviews.pyで10秒time.sleep(10)入れてみました。
views.pyのdef exec_ajax(request, pk):内のretunの前にtime.sleep(10)
import timeも忘れずに入れる。
detail.htmlのtimeout: 5000→15000
これでGETボタンを押すと「通信中」が10秒表示されて
エラーにならないことが確認できました。
しかしtime.sleep(60)ではPaizaCloudで1分を超えると
サーバー側でエラーになったので断念。
サンプルプログラム
最後にサンプルプログラムはこちら
ちなみに当初の目的であったスクレーピングのプログラムは公開後
思わぬ問題があって削除しました。
その状況
目次へ
このブログを書いているイチゲをOFUSEで応援する
MENTAやってます(ichige)
コメント