Windows11にインストールしてWindows標準のWindows PowerShellで
ChatGPTみたいにChatできました。
インストールもsetupファイルをダウンロードと
PowerShellで1個コマンド打てばすぐ動きました。
インストールで消費したストレージ4Gと思ったより少ない。
私のパソコン
- Windows 11 Home
- AMD Ryzen™ 3 4300G プロセッサー
- 16GB(8GB×2)メモリ(購入後8GB1個増設した状態)
GPUはないものと思っていましたが、タスクマネージャのプロセスのGPUの欄に
「AMD Radeon™ グラフィックス」っていうのが出てました。
ちょっと調べたら、こんな記事を見つけました。
Llama 2などの大規模言語モデルをローカルで動かせるライブラリ「Ollama」がAMD製グラボに対応
でも、「AMD Radeon™ グラフィックス」しかわからなくて対応してる型番か不明。(調査中)
それに以下の今回の方法ではGPUで動かすモードに特に設定してないのでcpuで動いていると思われる。
Directx診断ツールで調べた結果
名前:AMD Radeon(TM) Graphics
チップの種類: AMD Radeon Graphics Processor (0x1636)
DACの種類: Internal DAC(400MHz)
デバイスの種類:フル ディスプレイ デバイス
メモリ合計:8369 MB
表示メモリ(VRAM): 495 MB
共有メモリ: 7874 MB
日本語チャットも何も設定しないでできました。
しかし返答するまでは数十秒かかります。
返答文も少しとんちんかんな場合があったりします。というか話が長い。
実用面ではChatGPTやBing,GeminiなどWEBで使えるものがあるから
あえてこれを使う必要はないですが。
自分のパソコンで言語モデルが動くことが確認したい人にとってはとてもお手軽です。
まず動くことが確認できればもっと大きなモデルや
LLMを利用したRAGなどのプログラミングに徐々に入っていけると思います。
今回インストールするオープンソースの大規模言語モデル(LLM)をローカルで実行できるツールOllamaは、Windows の場合、最近対応したみたいで(preview2024/6/3現在)になっていて
正式版ではないかもしれません。
PowerShellでChatの他にブラウザの拡張機能を入れるとブラウザでも操作できます。
参考:Windows版 Ollama と Ollama-ui を使ってPhi3-mini を試してみた
次のステップのためOllamaのAPI入出力が、どんな感じなのかPowerShellで確認します。
また、AnacondaのPythonを使って操作してみます。

Ollamaを使うよりこっちのほうがおすすめです!

用語
まずは用語の解説からBingに聞いて少し手を加えた。
Phi-3-mini
Phi-3-miniは、Microsoftが開発した小型の言語モデルで、3.8Bのパラメータを持ちながら、大きなモデルと同等の性能を発揮するとされています。このモデルは、スマートフォンなどの小型デバイスでも動作可能で、4Kトークンと128Kトークンに対応しています。Phi-3-miniは、3.3兆トークンでトレーニングされ、SFTとDPOで微調整されており、言語処理やコーディング、数学の問題解決において優れた能力を示しています。。
Ollama
Ollamaは、オープンソースの大規模言語モデル(LLM)をローカルで実行できるツールです。LLama2やLLava、vicuna、Phiなどのモデルを個人のPCやサーバーで動かすことができ、
CLI(私はWindowsPowerShell使ってる)またはAPIを通じて操作することができます。開発者はOllamaを使用して、テキスト生成、マルチモーダル推論、Embeddingなどの機能を手元で試すことができるため、AI技術の実験や開発がより身近なものになります。
インストール
Ollamaをインストールすれば言語モデルのphi3はコマンド一つでインストールできます。
Ollamaをインストールします。
https://ollama.com→ダウンロード→Windowsをクリック→Download for Windows (Preview)をクリック
そのボタンの下にRequires Windows 10 or laterと対象が書いてある。
ダウンロードしたファイルOllamaSetup.exeサイズ204M
どのくらいの容量使うのか確認しときます。
exeファイル実行前、私のパソコンのストレージ
空き62.7GB
→(ここから後でやります。結果だけ)install後60.9GB→ollama run phi3後58.8GB
全部で4Gストレージを消費しました。思ったより全然少なかった。
OllamaSetup.exeをダブルクリック→install
インストールが完了した状態では、まだ動きません。
目次へ
Ollama-ui
これは入れなくても後述のPowerShellだけで動きます。
一応、試しました。
クロームのウェブストア↓にいくと
https://chromewebstore.google.com/detail/ollama-ui/cmgdpmlhgjhoadnonobjeekmfcehffco?hl=ja
私はEdgeで見てるので上に「olama-uiはMicrosoft Edgeで動作ます。」と出てきたので
「拡張機能を入手」
→「他のストアから拡張を許可する」と出たので「許可」をクリック
→拡張機能を追加
まだ、この段階では動きませんが画面だけは見れます。
Edgeの右上の拡張機能ボタンを押すとolama-uiがあるのでクリックすると画面が出ます。
目次へ
ollama起動/停止とモデルのダウンロード
起動
WindowsPowerShellを立ち上げ
ollama run phi3
これだけで言語モデルphi3のダウンロードとollamaの起動ができます。
ダウンロードは初めての時だけで、2回目以降はダウンロードがないので立ち上がりは速いです。
実際にダウンロードしたのはphi3-miniのようです。
後述するコマンド/show infoで確認したら
パラメータ数Parameter Size3.8B(38億)なのでphi3-miniのパラメータ数です。
完了したら
>>> Send a message (/? for help)
となったので「動いた」と入力してEnterしたら>>> 動いた
この文は、日本語で「動いた」と訳される。日本語における「動いた」は、ある対象が動き始めた状態を表す言葉です。例えば
、果物が開かれたり、木々が風に影響を受ける時などで使われます。この文形は自然現象や動物、あるいは人間の行動などと絡め
て使用されることが多いです。略動いてることが分かった。
使った感想。
途中から英語になるときがある。
cpuファンが、「いつもより多く回してます」状態でかなり処理してそう。
本格的にAIで何かやるならGPUがないとつらいと感じた。
拡張機能olama-uiを入れてる場合は、
Edgeの右上の拡張機能ボタンを押すとolama-uiをクリックして
「あなたは何ができますか」→sendで以下になった。
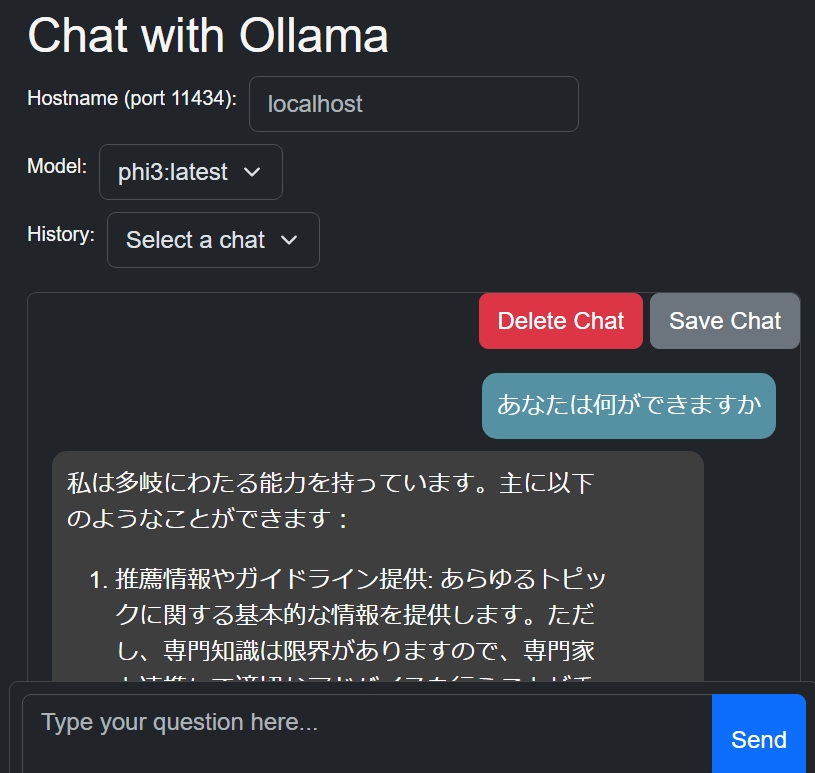
HELPと便利なコマンド
PowerShellで
/? EnterでHelpが表示される。
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
モデルの情報を見てみると
>>> /show info
Model details:
Family phi3
Parameter Size 3.8B
Quantization Level Q4_K_Mバージョン確認
ollama --version
ollama version is 0.1.41
停止(ターミナルのやり取りが停止するがOllama自体は動いてる(後述))
/bye
話が長いときCTRL+Cで止まります。
起動(phi3のダウンロードは初回のみ実行される。2回目以降はすぐ立ち上がる)
ollama run phi3
Clear session context
/clear
これ結構、使えます。話題をかえるときはクリアするといいです。
例えば、英語で質問したあと、日本語で質問しても英語で答えますが
/clearして日本語で質問すると日本語で答えるようになります。停止/再起動
/byeしても動いてる。タスクバーの通知領域にいました。
Quit Ollamaで終了します。
ターミナルでollama run phi3で再起動します。
また、スタートアップアプリに登録されているのでパソコン起動時に起動されます。
私はスタートアップでOllamaは無効化して使うときにターミナルでollama run phi3します。
目次へ
API
ollamaはport番号11434を使ったサーバーとして動いているようです。
APIが動くか確認してみます。
APIのドキュメントhttps://github.com/ollama/ollama/blob/main/docs/api.md
まずブラウザ(Edge)で確認できるか見てみます。
ブラウザ(Edge)でhttp://localhost:11434/にアクセスするとOllama is runningと表示される。
一応、念のため自分のIPアドレスを調べて、ipの後ろに:11434をくっつけてブラウザでアクセスしたけど「接続が拒否されました。」になった。
プロバイダーでブロックしているかWindowsで外部開放してないと思われる。
通知領域のOllamaをクリック→Quit Ollamaで終了するので
http://localhost:11434/もアクセスできなくなります。
ブラウザのアドレスバーではPOSTメソッドができないので、これ以上確認できることは多分ないです。
POSTメソッドができるWindows PowerShellのInvoke-WebRequestコマンドを使います。
目次へ
Show Model Information
APIの中で簡単そうなやつで、情報を見れるshowを試してみます。
ドキュメント
https://github.com/ollama/ollama/blob/main/docs/api.md#show-model-information
POST /api/showで見れるようです。
ドキュメントにはcurlを使う例はありますがWindowsはcurlがないので(←あるみたい?)
代替のInvoke-WebRequestを使います。
いろいろ実験して以下で実行できました。
Windows PowerShellを立ち上げて
ドキュメントの例にあるこれはWindowsでは動きませんでした。
curl http://localhost:11434/api/show -d '{
"name": "phi3"
}'Windows用に修正
$headers = @{"Content-Type" = "application/json"}
$body = @{name = "phi3"} | ConvertTo-Json
Invoke-WebRequest -Uri "http://localhost:11434/api/show" -Method POST -Headers $headers -Body $body
実行結果
StatusCode : 200
StatusDescription : OK
Content : {"license":"Microsoft.\nCopyright (c)
略
ちゃんと中身が見たい場合
$response =Invoke-WebRequest -Uri "http://localhost:11434/api/show" -Method POST -Headers $headers -Body $body
$response.Content
実行結果
{"license":"Microsoft.\nCopyright (c) Microsoft Corporation.略
"modelfile":"# Modelfile generated by \"ollama show\"\n# To build a new Modelfile based on this, replace FROM with:\n# FROM phi3:latest\n\nFROM C:\\Users\\user\\.ollama\\models\\blobs\\略,"details":{"parent_model":"","format":"gguf","family":"phi3","families":["phi3"],"parameter_size":"3.8B","quantization_level":"Q4_K_M"}}
目次へ1. Content-Type ヘッダーの設定:
$headers = @{"Content-Type" = "application/json"}- この行は
$headersという名前のハッシュテーブルを作成します。 - ハッシュテーブルは、データを格納するために使用されるキーと値のペアのコレクションです。
- この場合、キーは
"Content-Type"で、値は"application/json"です。 - このヘッダーは、サーバーにリクエスト本文が JSON データを含むことを通知します。
- この行は
2. JSON データの作成:
$body = @{name = "phi3"} | ConvertTo-Json- この行は、
"name"という名前のプロパティを 1 つ持つカスタム オブジェクトを作成し、その値に"phi3"を割り当てます。 @{...}シンタックスは、1 つのキーと値のペアを持つハッシュテーブルを作成するための省略形です。- このオブジェクトの出力は
ConvertTo-Jsonコマンドレットにパイプされ、オブジェクトを JSON 形式の文字列に変換します。 - 結果の JSON 文字列は
$body変数に格納されます。
- この行は、
3. POST リクエストの実行:
Invoke-WebRequest -Uri "http://localhost:11434/api/show" -Method POST -Headers $headers -Body $body- この行は、
Invoke-WebRequestコマンドレットを呼び出して、指定された URL に POST リクエストを送信します。 -Uri "http://localhost:11434/api/show": これは、リクエストのターゲット URL を定義します。ポート 11434 で実行されているローカル サーバー上の API エンドポイント (/api/show) を指します。-Method POST: これは、使用する HTTP メソッドを指定します。この場合、POST はデータを送信するために使用されることが多いため使用されます。-Headers $headers: このパラメータは、Content-Type ヘッダーを含む$headersハッシュテーブルをリクエストに渡します。-Body $body: このパラメータは、$body変数に格納された JSON データをリクエスト本文として送信します。
- この行は、
全体的な機能:
このコードスニペットは、API エンドポイントに POST リクエストを送信し、おそらくデータ (名前が “phi3” のオブジェクト) を送信します。 Content-Type ヘッダーは、サーバーがリクエスト本文を JSON として正しく解釈することを保証します。
補足:
- 必要に応じて、
"http://localhost:11434/api/show"を実際のターゲット API エンドポイントの URL に置き換えてください。 - API が期待するデータ形式に合わせてオブジェクト (
@{name = "phi3"}) を修正します。 - API の応答は実装によって異なります。シナリオによっては、
ConvertFrom-Jsonなどの方法 (ここでは示されていません) を使用して応答を解析する必要がある場合があります。
Generate a completion
“prompt”に書いた質問に対してresponseが返ってきます。
ドキュメントhttps://github.com/ollama/ollama/blob/main/docs/api.md#generate-a-completion
ドキュメントの例
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why is the sky blue?"
}'Windows用に修正
$headers = @{"Content-Type" = "application/json"}
$body = @{model = "phi3";prompt = "Why is the sky blue?"} | ConvertTo-Json
$response = Invoke-WebRequest -Uri "http://localhost:11434/api/generate" -Method Post -Body $body -ContentType "application/json"追記
$body = @{model = "phi3";prompt = "Why is the sky blue?"} | ConvertTo-Json
↓これにすると後述の$response.RawContentの1文字ずつ出力するのをやめてくれる。
$body = @{model = "phi3";prompt = "Why is the sky blue?";"stream" = $false} | ConvertTo-Jsonresponse表示
$response結果
StatusCode : 200
StatusDescription : OK
Content : {123, 34, 109, 111...}
RawContent : HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/x-ndjson
Date: Tue, 04 Jun 2024 06:48:17 GMT
{"model":"phi3","created_at":"2024-06-04T06:48:17.6256158Z","response":" The","d...
Headers : {[Transfer-Encoding, chunked], [Content-Type, application/x-ndjson], [Date, Tue, 04 Jun 2024 06:48:
17 GMT]}
RawContentLength : 23743詳細表示
$response.RawContent結果
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/x-ndjson
Date: Tue, 04 Jun 2024 03:19:31 GMT
{"model":"phi3","created_at":"2024-06-04T03:19:31.8227581Z","response":" The","done":false}
{"model":"phi3","created_at":"2024-06-04T03:19:31.9208393Z","response":" sky","done":false}
{"model":"phi3","created_at":"2024-06-04T03:19:32.0159868Z","response":" appears","done":false}
{"model":"phi3","created_at":"2024-06-04T03:19:32.111853Z","response":" blue","done":false}
略
{"model":"phi3","created_at":"2024-06-04T03:19:57.0646299Z","response":"","done":true,"done_reason":"stop","context":[32010,3750,338,278,略}テキストファイルに出力
$response.RawContent | Out-File -FilePath "C:\Users\user\Downloads\rawcontent.txt"rawcontent.txtを解析してみると
- Content-Type: application/x-ndjson: このヘッダーは、レスポンスの本文のデータ形式を示しています。
application/x-ndjsonは、新しい行ごとにJSONオブジェクトが含まれる形式です。ndjsonは、JSONデータを効率的に処理するために使用されます。 context: これはモデルが過去のトークンを参照するための情報です。モデルは過去のトークンを考慮して次のトークンを生成します。この数値は、過去のトークンの位置を示しています。response: これはモデルが生成した応答の一部です。例えば、"response": "The sky appears blue"というトークンがあれば、モデルは「空が青く見える」という文を生成していることを示しています。done: これはモデルが応答を完了したかどうかを示すフラグです。trueの場合、モデルは応答を終了しています。
一文字(トークン)ずつ送信してきて、doneがfalseのときは、まだ続きがあってtrueで終了。
contextはトークンを参照するための情報で、トークンの変換テーブルがないと変換ができない。(どこかにあると思うが)
生のデータを使う場合、青色の文字を取り出して表示すればいいと思います。
追記→;”stream” = $falseにすれば解決
目次へ
Python
JupiterNotebookでrequestsでやってみる
PowerShellのInvoke-WebRequestでやったことを
PythonのrequestsライブラリのPOSTに置きかえてやってみました。
以下、JupiterNotebookで実行したら同じようにollamaのレスポンスが見れました。
import requests
url = "http://localhost:11434/api/generate"
headers = {"Content-Type": "application/json"}
data = {"model": "phi3", "prompt": "What is highest mounten in Japan?"}
response = requests.post(url, json=data, headers=headers)
# レスポンスの内容を表示
print(response.status_code) # ステータスコード
print(response.text)続けて以下を実行するとresponseを1個づつ取り出して半角スペースでつなげられます。(自作)
import json
response_lines = response.text.split('\n')
responses = []
for line in response_lines:
if line.strip(): # Ignore empty lines
response_json = json.loads(line)
if not response_json.get("done", True):
responses.append(response_json.get("response", ""))
final_response = ' '.join(responses)
print(final_response)結果
The highest mountain in Japan is Mount Fu ji , also known as F uj isan . Its official height is 3 , 7 7 6 . 2 4 meters ( 1 2 , 3 8 9 feet ), making it an icon ic symbol of Japan and a significant site for pil gr image and tour ism . Loc ated on H ons hu Island , near the Pacific coast in Ch Å« bu region , Mount Fu ji is not only famous for its impress ive height but also for its nearly perfect con ical shape , which has been rever ed as one of the country ' s cultural icons since at least the 7 th century . In 2 0 1 3 , Mount Fu ji was designated a World Heritage site by UN ES CO along with ten other places that illustrate the culture and history surrounding it .一応responseから文章として取り出せているが、
これだと単語の途中でスペースが入ってしまう。
data = {"model": "phi3", "prompt": "What is highest mounten in Japan?"}
↓これに変えると1文字ずつ出力するのをやめてくれる。
data = {"model": "phi3", "prompt": "What is highest mounten in Japan?","stream":False}結果
200
{"model":"phi3","created_at":"2024-06-05T00:18:38.6498031Z","response":" The highest mountain in Japan is Mount Fuji. Its peak stands at an impressive altitude of approximately 3,776 meters (12,389 feet) 略ただし出力するまで、すごい遅く感じます。それは全部出力したあとでないと表示しないからです。
PowerShellでやっているときは、1文字(1トークン)ずつ出力するので速く感じます。
かといって,”stream”:Falseを消しても全部出力するまで表示しないのは変わらずrequestsでは、
その辺の対策ができないかもしれません。
langchain_communityを使う
次にomallaの入出力を簡単にPythonで、できるようになっていたので、それを使ってみます。
新たに仮想環境を立ち上げる必要はないかもしれませんが
なんとなく失敗したときに、この環境だけ消せば被害が少なくて済むかなという漠然とした安心感で仮想環境作ります。
例えば、気になるのはcondaじゃなくてpip使って大丈夫かとか。
いつもメインの環境は標準ライブラリだけで使っているので。
多分pipしても、この仮想環境だけ入るだけで他には影響ないと思います。
それではやっていきます。
Anaconda Navigatorを立ち上げ
環境の名前(ollamatestと付けました)を付けてCreate
OpenTerminal
mkdir ollamatest
cd ollamatest
code .
でVsコードを立ち上げる。やることは
ドキュメントUsing LangChain with Ollama in Pythonに書いてある通り
pipしてコード数行で出来ます。
pip install langchain_communitytest.pyというファイルを新規作成
from langchain_community.llms import Ollama
ollama = Ollama(
base_url='http://localhost:11434',
model="phi3"
)
print(ollama.invoke("why is the sky blue"))
表示→ターミナルで()の中が仮想環境名になっていることを確認
なっていないときは右下のほうをクリックすると「インタープリタの選択」ができるので
仮想環境名を選ぶ。
(ollamatest) PS C:\Users\user\ollamatest>pip install langchain_community
実行
(ollamatest) PS C:\Users\user\ollamatest> python test.py
結果
The sky appears blue to us because of a phenomenon called Rayleigh scattering. As sunlight reaches Earth's atmosphere, it is composed of various colors that correspond to different wavelengths of light. Blue light has shorter wavelengths and higher energy compared to other visible colors like red or yellow.略これも全部出力されてから表示してるので遅く感じてしまう。
目次へ
stream出力できるのがあった(ollama-python)
これだとstream出力(1単語づつ表示)できます。
参考https://github.com/ollama/ollama-python/blob/main/README.md
pip install ollamaimport ollama
stream = ollama.chat(
model='phi3',
messages=[{'role': 'user', 'content': '日本で1番高い山は'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)所感
もともと言語モデルをパソコンに入れるのはGPUがないとダメだろな~
言語モデルのAPIは有料だしな~
無料のAPIないかな~という感じで探してたらollamaを見つけました。
これで言語モデルを使ったプログラミングができそうです。
(追記)無料API見つけました。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
目次へ