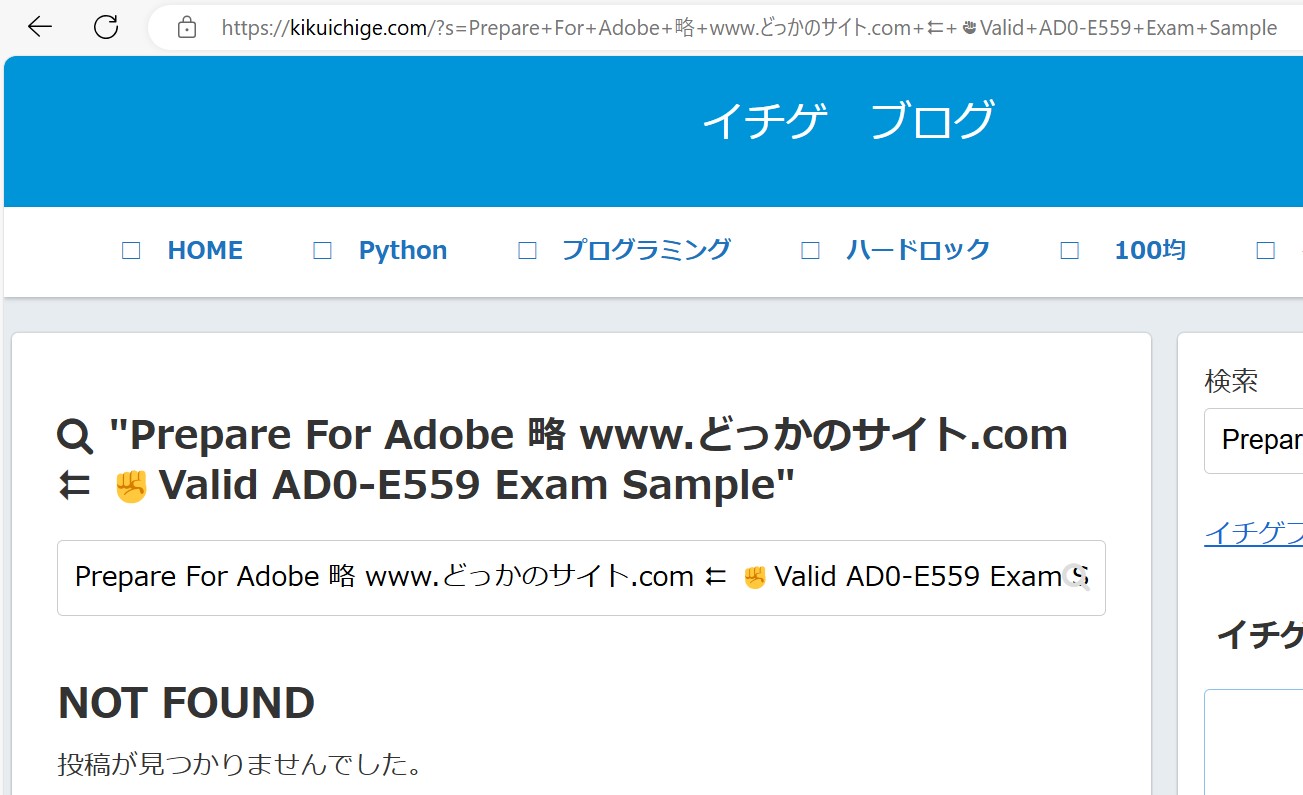
アクセスログを見ていたら/?s=~というのがあった。
これはサイト内検索を利用したスパムらしい。
アクセスログやGoogle Search Console、ブラウザの検証ツールを使って
多角的に調べてみた。
またGoogle Search Consoleでインデックスされていないページの原因を調査します。
アクセスログ
ログにこんなのがあった。
(いろいろ私が変えて貼り付けてります。本物は絵文字とか使って、サイトの宣伝になってます。)
同じようなものを見つけても、そのサイトについて見に行ったりしないほうがいいと思います。
"GET /?s=Prepare+For+Adobe+略+www.どっかのサイト.com+%E2%AE%84+%E2%9C%8AValid+AD0-E559+Exam+Sample HTTP/2.0"
これは
https://kikuichige.com/?s=Prepare+For+Adobe+略+www.どっかのサイト.com+%E2%AE%84+%E2%9C%8AValid+AD0-E559+Exam+Sample
というアクセスをしたということです。
ポイントは赤い部分でドメインの後ろにurlパラメータで?s=任意の文字とすると
サイト内検索ができます。
その検索ワードに、どこかのサイトのurlをくっつけた文字列を書いてます。
実際にアクセスすると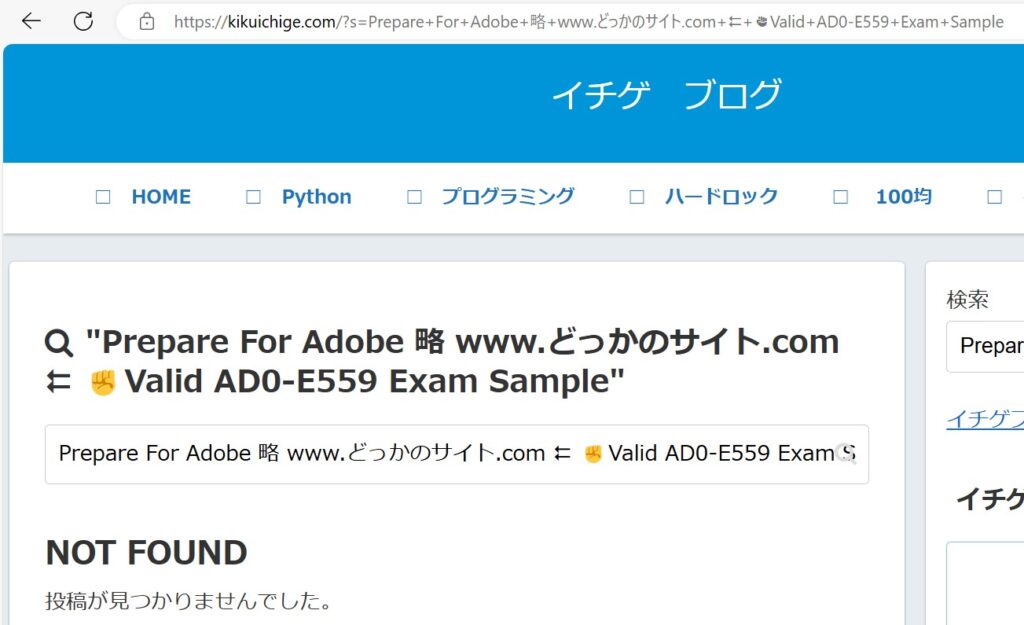
何が問題か
サイト内検索スパムの例
- キーワード詰め込み
- スパマーは、特定のキーワードで検索を繰り返し、検索結果ページにそのキーワードを表示させることで、検索エンジンのクロールボットにそのキーワードを多く含むページとして認識させようとします。
- 自動検索スクリプト
- ボットやスクリプトが自動的にサイト内検索を実行し、サーバーのリソースを消費させ、サイトのパフォーマンスを低下させます。
- 悪意のあるリンク
- スパマーが検索クエリに悪意のあるリンクを含め、検索結果ページにそのリンクを表示させ、ユーザーを悪意のあるサイトに誘導します。
- 重複コンテンツ生成
- 同じ検索クエリを繰り返し実行することで、検索結果ページが大量に生成され、重複コンテンツが増え、SEOに悪影響を与えます。
1と4は、この検索結果画面をGoogleがインデックス対象にしてしまうことが
問題を引き起こしている。
目次へ
Google Search Consoleでインデックスされているか確認
インデックス登録済みの確認
Google検索にインデックス(Google検索したときに検索結果として表示する対象になるurlのこと)
されているかGoogle Search Consoleで確認できる。
Google Search Consoleの左側のインデックス作成→ページをクリックすると
ページのインデックスの登録が表示される→インデックス登録済みページのデータを表示をクリック
するとインデックスされているurlが表示される。
ただし次のような理由で省略されることがあるみたい。
- 表の行数の制限(1,000 項目)
- インスタンスが最後に試行されたクロールの後に発生した
実際、2024/5/24に確認したら2/19~5/21にクロールした結果しかなかった。
インデックス未登録の確認
ひとつ前の画面に戻って「ページがインデックスに登録されなかった理由」のところに
クロールされたけどインデックスされていないurlと理由が書かれている。
理由の「noindex タグによって除外されました」をクリックすると
以下のurlがあった。
https://kikuichige.com/?s=H21-711_V1略+www.別のサイト.com+略Fragen+Beantworten検索結果がなぜインデックスされるのかは不思議です。
普通、投稿した記事や、プロフィールなどの固定ページが対象のはずです。
しかも上のようなurlでページをつくっているわけでもない。
しかし、上のurlにアクセスすると検索結果のページが表示される以上、
コンテンツとして成り立っています。同じurlにアクセスすればいつも表示できます。
もう一つなぞなのは、なぜGoogle クローラーは、このurlをクロールしたかです。
Geminiに聞いたら
Googleは、様々な方法で新しいウェブページや更新されたページを発見します。
主な方法は以下の通りです。
- 過去のクロールで発見したウェブページに記載されているリンクをたどる
- サイトマップやRSSフィードなどのファイルからURLを取得する
- ブラウザユーザーがGoogle検索で入力したキーワードに関連するウェブページを推測する
ということでした。
サイトマップやRSSフィードというのはドメインが、
どんなurlを持っているかの情報が出てます。
サイトマップはWordPress 5.5 以降では、WordPress 本体に XML サイトマップの自動生成機能が備わっており、デフォルトで有効になっています。
私のサイトの場合https://kikuichige.com/wp-sitemap.xmlの中のhttps://kikuichige.com/wp-sitemap-posts-post-1.xmlにURL一覧があります。
WordPressサイトには、初期状態で独自のデフォルトRSSフィードが生成されています。
アクセスするには、サイトのURLの末尾に「/feed」を追加します。
私のサイトの場合https://kikuichige.com/feed/
サイトマップやRSSフィードを見た限り、普通にこちらが公開しているurlしかありません。
どうしてkikuichige.com/?s=~のurlをGoogle クローラーが発見したのか?
アクセスログに残っている瞬間しか存在していなかったページなのに不思議です。
この種の攻撃はアクセスログを見ると毎日されています。
しかしGoogle クローラーが発見してインデックスしようとした痕跡があるのは
Search Consoleで3か月で1回しかありませんでした。
なので全部が全部、Google クローラーに発見されてるわけでもなそうです。
またSeach Consoleを見ると
wp-adminなどWordPressの管理画面をインデックスしようとしたりしてるので
Google クローラーの探索方法はちょっと変です。
目次へ
対策
Google Search Consoleで見るとインデックスされていないのだから
インデックスされる件に対しては対策済みと考えられます。
なぜインデックスされなかったかはSearch Consoleの理由に書いてあるように
「noindex タグによって除外されました」からです。
私の使っているWordPressテーマCocoonの場合、こちらにあるように
サイト内検索結果ページはデフォルトでnoindex(Googleクローラーがインデックスしないようにする)をつけてくれてるみたいです。
実際に確認してみます。(ドメインの後ろに/?s=任意の文字でアクセスする)
私の場合https://kikuichige.com/?s=任意の文字
Edgeの場合、表示されたページで右クリック→開発者ツールで検証
</>要素タブを見ると
<head>
略
<meta name="robots" content="noindex, follow">
略
</head>実際にnoindexがついていることが確認できました。
ということで、この件に関しては対策済みということで放置することにしました。
目次へ
Google Search Consoleでインデックスされていない原因を調査
ここからは別件で、インデックスされていないものの原因を調査します。
「ページがインデックスに登録されなかった理由」のところに
理由が書いてあります。クリックすると該当するページが表示されます。
一つずつ見ていきますが、ソースがウェブサイトではじかれているページは
別にインデックスしてくれなくていいurlばかりでした。
むしろソースがGoogleシステムになっているurlのほうにインデックスしてもらいたいurlがあります。
なのでここに分類されているものをなくすことが重要ではないかと個人的には思ってます。
ページにリダイレクトがあります
該当ページが170ありました。
そのurlにアクセスしたらリダイレクトするのだから、
リダイレクト先をインデックスしますということだと思います。
ほとんどの場合、WordPressの自動補完リダイレクト機能によってリダイレクトされている。
私の場合は、パーマリンク(Webサイトのページ毎に設定しているURL)を
1番最後が/で終わるよう設定している。(具体的には/%post_id%/)
これはWordPressのダッシュボードで設定→パーマリンクで確認できます。
なので最後に/を入れないでアクセスされた場合
自動的に最後に/を付けてリダイレクトするようにWordPressがしてくれてます。
例:https://kikuichige.com/7920にアクセスすると
https://kikuichige.com/7920/に自動的にかわります。
これが原因でhttps://kikuichige.com/7920が
「ページにリダイレクトがあります」に振り分けられてます。
そもそもhttps://kikuichige.com/7920をGoogleクローラーが
インデックスしようとしたか考察すると
私が自分でhttps://kikuichige.com/7920と/なしで
別の記事の中にリンクを貼っているのかもしれません。
こんなのもあります。https://kikuichige.com/8686//1000
どっから/1000が出てきて、なぜインデックスしようとしたか不明です。
ただ、アクセスログ見てると最後に/1000つけたアクセスログを見るので
何か攻撃手法があるのかもしれません。
/ありのページがインデックスされていないわけではないので、
ここは気にせず放置してます。
目次へ
noindex タグによって除外されました
これはmetaタグにnoindexが書いてあるからです。前述しました。
前述した1個以外は全部feedがついたurlでした。
feedに関しては、こちらを参照してください。
実際アクセスするとhttps://kikuichige.com/25118/feed/
noindexは見当たらない。
というのもクロールされている日と現在では途中で
私のサイトをレンタルサーバーからVPSに変更しているので設定が違う。
ちょっと調べるとHTTPレスポンスヘッダーにX-Robots-Tag: noindexというパターンもあるらしい。
なのでクロールされた当時はあったかも。
feedに関してはインデックスしてもらう必要はないので、このまま放置。
見つかりませんでした(404)
urlを変えたりして存在しないものをインデックスしようとしたからです。
該当のurlをクリックすると404 NOT FOUNDになります。
目次へ
アクセス禁止(403)が原因でブロックされました他の 4xx の問題が原因でブロックされました
ここに分類されるのはwp-adminとかwp-jsonです。
これらは管理画面などでインデクスされては困るものなので、これでいいです。
もしインデクスしてほしいurlが分類されてたら恐らくサーバー側の問題と思われます。
つまりサーバー側でアクセス禁止または動作がおかしくてエラーになっているためです。
403以外の 4xxは
400エラー(Bad Request)(クライアントから送信されたリクエストがサーバーで処理できなかったことを示すエラーコード)などが出ます。
robots.txt によりブロックされました
robots.txtでDisallowに書いたディレクトリ内が対象になります。
設定をクリックするとクロールのところにrobots.txtと出てる。
レポートを開く→該当するrobots.txtをクリックすると内容が見れる。
私のrobots.txt
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://kikuichige.com/wp-sitemap.xmlrobots.txtはシンクラウド for Freeのものを流用した気がする。
そういう気がするのはrobots.txtを書いた覚えがないから。
さらにサーバーを血眼になって探しても見つからない。
で分かったのがhttps://naifix.com/robots-txt/#_robotstxt
抜粋「WordPress は「robots.txt にアクセスがあった場合に自動生成される」仕組みになっています。」。ガーン😨
robots.txtはGoogleクローラーだけが対象ではない。
Allow:にしている /wp-admin/admin-ajax.phpはWordPressで設定を更新するときに
実効されるものです。こちらWAFで引っかかったときに調べた記録です。https://kikuichige.com/23256/#toc2
この設定、本当に必要か、ちょっと調査したほうがいいかもしれないと思いました。
環境によって違うと思うので、なくしたら問題起きるかもしれないけど。
でもrobots.txtの Allow: を消してたものを作ってルートに置いてもいいけど、
その場合、自動生成のrobots.txtとかぶらないのかとか気になるし、
WordPressがデフォルトで作っているものだし、
まあ、いいかということでこのままにしました。

実際に「robots.txt によりブロックされました」にのっていたもの
https://kikuichige.com/wp-admin/post.php?post=12198&action=edit
https://kikuichige.com/wp-admin/widgets.php
まあ、こんな管理画面関係のurlをインデクスされて検索結果にでてきたら危険なので
インデクスされなくっていいです。
目次へ代替ページ(適切な canonical タグあり)
8個ありました。
ChatGptの解説をベースに具体的に見てみると。
このタグは 正規化リンク (canonical link) と呼ばれ、ウェブページの正規なバージョンを指定するために使用されます。具体的には、同じコンテンツが複数のURLで利用されている場合、検索エンジンに対してどのURLが正規なものであるかを示す役割を果たします。
具体的に分類されていたurlを開いてみます。
https://kikuichige.com/?cat=0
Edgeの場合、表示されたページで右クリック→開発者ツールで検証
</>要素タブで見てみると
<head>の中に
<link rel="canonical" href="https://kikuichige.com/">
がありました。
ちなみにhttps://kikuichige.com/にも同じものがあります。
この場合、href 属性の値で指定されているURL https://kikuichige.com/ が、このページの正規なバージョンであることを示しています。検索エンジンはこの情報を利用して、重複したコンテンツを適切にインデックスすることができます。
WordPressの場合、自動で全部に<link rel="canonical" href="リンク先は自分自身">がつくみたいです。
(?cat=0は、カテゴリIDが0のものを表示してるようです。
カテゴリid0はないので多分、全ページ表示してます。)
ただurlパラメータが後ろについてるhttps://kikuichige.com/?cat=0のような場合は
urlパラメータを含んだものはcanonicalタグは作られてません。
分類されてるものは全部urlパラメータ付きのもので
意味のないページをインデックスしようとしてたので放置です。
このように分類されているページに実際にアクセスして
canonicalタグを確認して判断すればいいと思います。
個人的にはcanonicalタグに、あまり利用価値は感じられません。
目次へクロール済み – インデックス未登録
これは重要で、どうにかインデクスさせたいurlです。
クロール済みでインデックスされないもの。
「クロール済み – インデックス未登録」という状態は、Google Search Consoleでよく見られるエラーメッセージの一つです。これは、Googlebotがページをクロール(読み取る)したものの、そのページがGoogleのインデックスに登録されていないことを意味します。この状態にはいくつかの原因があります。主な原因を以下に示します。
- コンテンツの質が低い:
- ページの内容が薄かったり、重複していたり、ユーザーにとって価値がないと判断されると、インデックスされないことがあります。
- 技術的な問題:
- ページにリダイレクトエラーやサーバーエラーがあると、Googleがページを正しくインデックスできません。
- ページがrobots.txtファイルでブロックされている場合も同様です。
- クロールバジェットの問題:
- 大規模なウェブサイトでは、Googleがクロールに割り当てるリソース(クロールバジェット)が限られているため、すべてのページがインデックスされない場合があります。
- メタタグの設定ミス:
- ページに「noindex」メタタグが設定されている場合、そのページはインデックスされません。
- インデックスポリシーの変更:
- Googleのアルゴリズムやポリシーが変更され、一部のページがインデックスから除外されることがあります。
「コンテンツの質が低い」と判断されたと考えるのが妥当だと思う。
しかし、この「コンテンツの質が低い」の判断基準があいまいだし
コロコロ変わっているのではないかと思われる。
以下、私のサイトのインデックス未登録のページです。
でも昔はインデクスされていたと思うので、外されたんだと思います。
気づいたら、どう変化してるか書いていこうと思います。
2024/5/24時点のクロール済み - インデックス未登録(私のサイト)
全部で145あるがカテゴリだったりfeedだったりインデックスしなくていいものも含まれていて
実質はじかれたページは以下16個です。
インデックスされているページは209個=225(公開ページ数)-16です。
ただ、数日たつと何もいじってないのに評価が変わっているものあった。
WEB表示よりエクスポートして見たほうが正確かもしれない。
後述するsite:で確認するとインデックスされていることもある。
気づいた範囲で変化を記録したいと思います。
個人基準で評価しました。
×内容が薄い。内容が古く現状とかけ離れている。独自性なし。まあ、しょうがない。
△テーマが危なっかしい、独りよがり日記みたい。まあ、しょうがない。
○頑張って書いたけど、情報が古かったり、あまり役に立たないかな~
◎なんでやねん!納得できない!
https://kikuichige.com/137/ 〇
https://kikuichige.com/284/ 〇
https://kikuichige.com/655/ ×
https://kikuichige.com/997/ ×
https://kikuichige.com/1214/ 〇
https://kikuichige.com/2344/ 〇2024/05/29インデックス登録された。
https://kikuichige.com/3125/ 〇
https://kikuichige.com/3521/ ×
https://kikuichige.com/5095/ 〇
https://kikuichige.com/12528/ △
https://kikuichige.com/12774/ △
https://kikuichige.com/23991/ ◎2024/05/30インデックス登録された。
https://kikuichige.com/24890/ ×
https://kikuichige.com/24948/ ◎
https://kikuichige.com/25268/ ◎2024/5/27インデックス登録された。
https://kikuichige.com/25676/ ◎2024/5/27インデックス登録された。
2024/05/25のクロールでインデクス登録から外された。
https://kikuichige.com/1810/ ○
2024/06/04のクロールでインデクス登録から外された。
https://kikuichige.com/1096/ ×
2024/06/08のクロールでインデクス登録から外された。
https://kikuichige.com/6408/ ×
https://kikuichige.com/3306/このページは対象期間に
何もいじっていないのに以下のような分類の移動をした。
2024/05/26に「クロール済み - インデックス未登録」になったが
2024/05/28は「インデックス登録済みページ数」になっていた。
Google検索でインデックスされているか調べる方法
インデックスされているか調べる方法にsite;でGoogle検索する方法もあります。
インデックスされてないサイトの場合
例:site:https://kikuichige.com/137/をGoogle検索すると以下が出ます。
「site:https://kikuichige.com/137/ に一致する情報は見つかりませんでした。」
インデックスされているサイトでやってみると
例site:https://kikuichige.com/184/をGoogle検索すると、
ちゃんとhttps://kikuichige.com/184/が出てきます。
ただ、「クロール済み - インデックス未登録」に登録されたばかりのものは
siteでも出てくるので、除外反映されるのが遅いかも。
目次へ検出 – インデックス未登録
ここはインデックスできる可能性があるのでインデックス登録のリクエストができます。
なのでリクエストしておきました。
2024/5/24時点の検出 – インデックス未登録(私のサイト)
https://kikuichige.com/1096/→2024/5/27インデックス登録された。
https://kikuichige.com/6408/→2024/5/27インデックス登録された。
https://kikuichige.com/17288/→2024/5/27インデックス登録された。
上の「https://kikuichige.com/」のすべてのURLを検査という欄に貼り付けてEnter
→「URL が Google に登録されていません」と出たら
→インデックス登録をリクエスト
→インデックス登録をリクエスト済みと出るのでリクエスト完了。
実際にリクエストたら3日後の2024/5/27に3つろもインデックス登録され
Google Search Consoleの「検出 – インデックス未登録」は0になっていた。
目次へ
重複しています。Google により、ユーザーがマークしたページとは異なるページが正規ページとして選択されました
カテゴリのスラッグを変えたら、数日後、出ました。
変更前のほうを正規URLとしてGoogleが認識してるようです。
「URL が Google に登録されていません」だから「インデクス登録をリクエスト」したくなりますが
多分、同じ結果になりそうです。
そのうちGoogleが変わったことに気づくだろうと判断して放置します。
古いほうを削除依頼してもいいかもしれないですが
何か怖いのでやめときます。
(誤解して全ページをインデックスから除外するとかやらかさないか心配なので)
表示されているURLをURL検査すると下のほうに以下が表示された。
ユーザーが指定した正規 URL
https://kikuichige.com/category/afurieito/blogafurieito
Google が選択した正規 URL
https://kikuichige.com/category/afurieito/wordpressブログ入門(アフィリエイト)/
こちらのURLは古いのでアクセスしても404 NOT FOUNDになる。
所感
Googleクローラーが、どういう基準でインデックスしようとしてるのか謎が多い。
サイトマップにあるものだけクロールしてほしい気はする。
そのための方策にエネルギーをかけてもいいが、あまり意味がないかもしれない。
ソースがGoogleシステムで、インデクスされていないページを
どうにかインデックスさせるほうにエネルギーをつかったほうがいい気はします。
イチゲをOFUSEで応援する(御質問でもOKです)Vプリカでのお支払いがおすすめです。
MENTAやってます(ichige)
目次へ